|
|
对于数据库的优化主要包括三个部分:查询优化、索引优化和字段类型优化,其中,索引优化则是数据库优化的重中之重。一个查询使用索引与不使用索引的差别可能只在100个数量级,而一个好的索引与不好的索引差别可能在1000个数量级,但是一个最优的索引与普通的索引查询效率可能就相差上万甚至更高的数量级。本文首先会介绍索引的存储结构,然后介绍单表查询使用的单列索引、联合索引、前缀索引等结构,最后会介绍一些困难谓词及不恰当的索引用法。
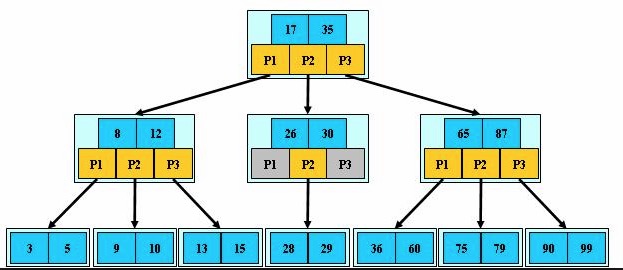
1. 索引结构索引典型的结构是B+树,B+树是平衡树的一种,但是和典型的平衡树不同的是B+树叶子节点上存储了多个元素,并且非叶子节点是由多个元素进行组织的。另外,B+树相对于B树的主要区别在于B+树的叶子节点上存在一个指向下一个叶子节点的指针,这样就便于对叶子节点的数据进行遍历。如下图所示是一个B+树的结构示意图(关于B+树的详细介绍请大家参阅相关的文档):
1.1 聚簇索引在数据库中,索引主要以两种形式存在:聚簇索引和二级索引。对于二者的区别,可以这么理解,数据库的数据是存储在磁盘上的,那么磁盘上的数据存储肯定是有一定的顺序的,这里聚簇索引就是指组织磁盘数据顺序的索引。对于数据库而言,其是可以存在多个索引的,而磁盘上的数据顺序只可能有一种,因而对于索引而言,一个表只可能有一个索引被定义为聚簇索引(默认是主键索引),其余的索引都属于二级索引。如下图所示为一个聚簇索引组织数据的示意图:
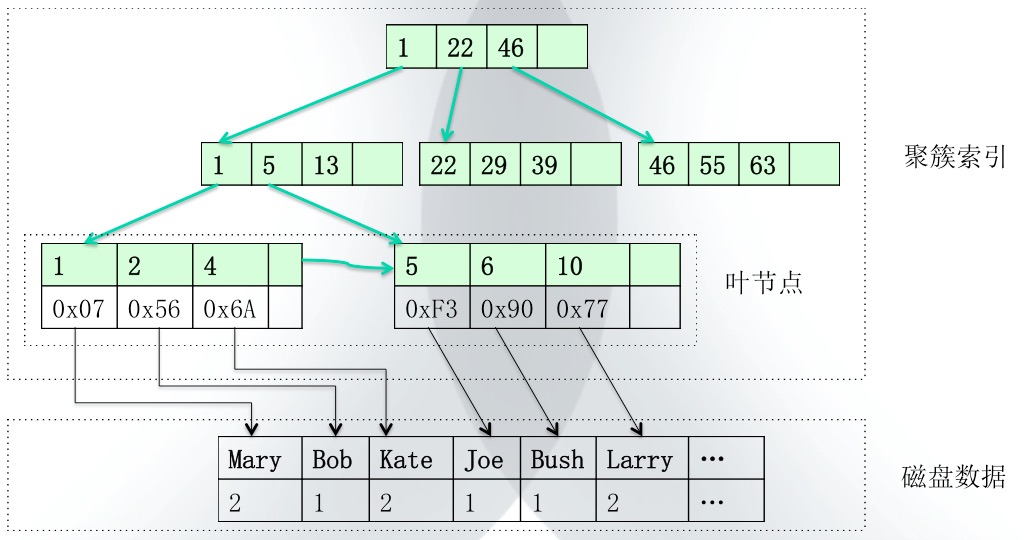
图中上部分的方框包含的部分就是聚簇索引,下部分方框中的部分表示磁盘数据。可以看到,聚簇索引的结构就是一棵B+树,B+树中每个节点中都包含有顺序组织的数据id,并且每个节点中都留有一部分余量,用来存放新插入的数据。这里主要需要注意的是,在聚簇索引的叶节点上不仅存储了当前数据的id,还存储了该id所指代的数据在磁盘中的地址,并且磁盘上数据的存储顺序与聚簇索引的叶节点的顺序是一致的。这里其实就可以看出来,在通过id查询时,数据库是先根据id定位到聚簇索引的叶节点,然后根据叶节点上数据的地址值获取磁盘上的数据的,由于索引一般存储在内存中,因而定位叶节点数据的消耗可以忽略不计。
这里需要说明的是,对于聚簇索引具体选择哪个索引作为聚簇索引是有一定规则的,具体的规则如下:
- 如果当前表存在主键,那么MySQL就会将主键作为聚簇索引;
- 如果表中不存在主键,那么MySQL就会查看当前表中是否存在非空唯一索引(无论是否为联合索引),如果存在,则以该联合索引作为聚簇索引;
- 如果以上两个条件都不满足,那么MySQL就会为表生成一个rowId作为聚簇索引。
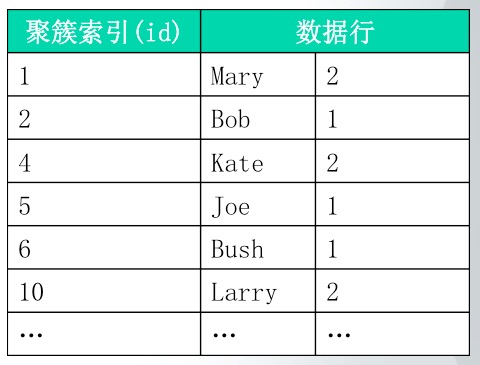
如下图所示是一个聚簇索引的简化示意图,可以看到,其和表结构基本是一致的:
1.2 二级索引对于二级索引,其也是以B+树的形式组织的,但其和聚簇索引最大的区别在于,其叶节点上不仅存储了当前索引列的数据值,还存储了该数据值所对应的磁盘数据的id。这里需要注意的是,如果磁盘有多条数据具有相同的值,那么在索引中其id会以列表的形式存储在叶子节点上。如下图所示为一个二级索引的示意图:
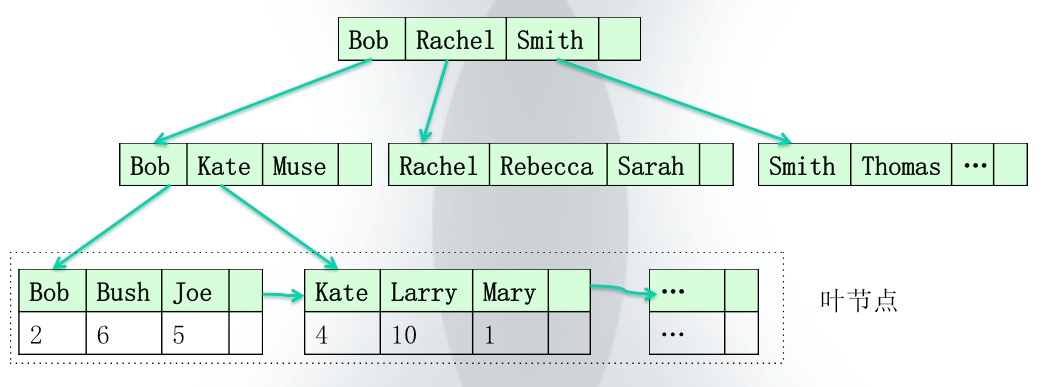
上图中的二级索引即前面为name字段建立的索引。可以看到,该二级索引的叶节点中不仅保存有当前字段的数据值,还保存有该数据对应的磁盘数据的id。
在使用二级索引进行查询时,MySQL首先会通过二级索引获取到所查询的数据对应的磁盘数据id,然后根据这些id在聚簇索引中查询磁盘数据,也就是说在使用二级索引进行查询时,其会进行两次索引的定位查询。如下图所示为使用二级索引进行查询的一个示意图:
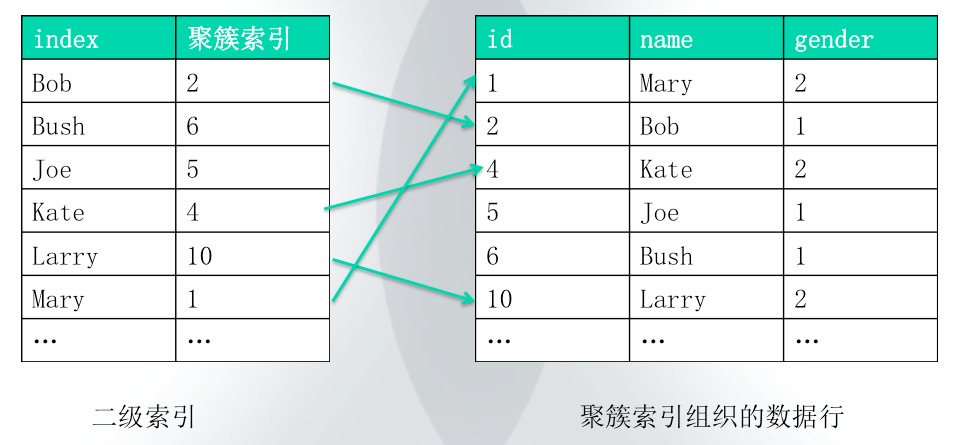
2. 单表索引本文所使用的测试表结构如下:
CREATE TABLE actor(
id BIGINT AUTO_INCREMENT COMMENT '主键' PRIMARY KEY,
first_name VARCHAR(255) DEFAULT '' NOT NULL COMMENT '姓',
last_name VARCHAR(255) DEFAULT '' NOT NULL COMMENT '名',
email VARCHAR(255) DEFAULT '' NOT NULL COMMENT '邮箱',
gender TINYINT DEFAULT '1' NOT NULL COMMENT '性别:1-男士,2-女士'
); |
文中使用的测试数据是使用程序生成的,具体的生成程序请克隆数据生成工具中的项目运行生成,部分示例数据如下:
mysql> select * from actor limit 10;
+-----+---------------------+---------------------+---------------------------------+--------+
| id | first_name | last_name | email | gender |
+-----+---------------------+---------------------+---------------------------------+--------+
| 1 | qWhNIZqxcbD | rxkPMBqBvWnzbJe | FKZUldeSggtZ@saN.vfS | 2 |
| 2 | sFsCUyFsmrrRbSOa | rMqChueZJThP | tZqaNHJwQEjwobA@UaJtk.oxr | 1 |
| 3 | rMqChueZJThP | YuzpZwrsYbCATXlsLxx | jiaPbEhUecygLj@lshCA.HKA | 1 |
| 4 | aFGRpVCdQjvJrvg | ynZBRNYgCfowzNtCqR | ZxqdOxFIYinQBs@NnoXI.xTfBo | 1 |
| 5 | RaGEPWLxepknJw | GOywmnVQEUtPNxSG | iNRUjDxGgbaKPZfGXE@MyMXc.QeHv | 2 |
| 6 | EQwbpQODEuFUs | aUSwXoIKosuVlcjiKJ | WQSeQtQHdoDXUbn@JeCo.Xrof | 1 |
| 7 | YbjiVKQfplqUAhNuKg | DqvNpyhPmMHgPPAF | qwXeylhiVkEYTnEne@PLab.NqE | 2 |
| 8 | mSSLjRlVPFfVhve | HXqDkQTfQwh | XkUfqzJdeoBdbuPZK@Urp.bsfc | 2 |
| 9 | mDZNpjfJJZOdB | rMqChueZJThP | XHNSFXfBRLG@IBFez.EMi | 1 |
| 10 | zPeLuNPfStQyny | qWhNIZqxcbD | sKupgyQxud@aUD.mce | 2 |
+-----+---------------------+---------------------+---------------------------------+--------+ |
该表数据量为1000w,各个字段的选择性如下:first_name 10% last_name 10% email 1% gender 50%。字段选择性指的是按该字段分组后,数据量最大的组的数据量占总数据量的比例,比如这里first_name中同一个值的数据最多为10w条。
2.1 单列索引 2.1.1 单列索引单列索引指的是在表上为某一个字段建立的索引,一般索引的创建选择整型或者较小的定长字符串将更有利于效率的提升,这里作为演示,我们对first_name字段建立了索引,如下所示为使用该索引与不使用索引时在actor表上相同的查询效率情况比较:
**SQL语句: ** select * from actor where first_name='rMqChueZJThP';
| | 索引 | 无索引 | first_name |
|---|
| 耗时 | 7.05s | 0.15s |
从查询结果可以看出,对于单字段查询,使用索引和不使用索引查询的耗时区别是非常大的。这里我们可以使用show profiles命令查看两次查询的详细耗时,关于show profiles的用法如下:
mysql> set profiling=1;
mysql> 执行SQL语句;
mysql> set profiling=0;
mysql> show profiles;
mysql> show profile cpu, block io for query 1; |
?最后一步中的query id是前一步中查询结果中相关查询的id。对于前述SQL语句的执行耗时的查询结果如下:
+----------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+----------------------+----------+----------+------------+--------------+---------------+
| starting | 0.000075 | 0.000070 | 0.000017 | 0 | 0 |
| checking permissions | 0.000019 | 0.000005 | 0.000002 | 0 | 0 |
| Opening tables | 0.000029 | 0.000019 | 0.000007 | 0 | 0 |
| init | 0.000048 | 0.000037 | 0.000006 | 0 | 0 |
| System lock | 0.000010 | 0.000008 | 0.000003 | 0 | 0 |
| optimizing | 0.000008 | 0.000007 | 0.000001 | 0 | 0 |
| statistics | 0.000016 | 0.000015 | 0.000000 | 0 | 0 |
| preparing | 0.000010 | 0.000009 | 0.000001 | 0 | 0 |
| executing | 0.000002 | 0.000001 | 0.000001 | 0 | 0 |
| Sending data | 7.051533 | 6.633832 | 0.366078 | 0 | 0 |
| end | 0.000011 | 0.000005 | 0.000005 | 0 | 0 |
| query end | 0.000007 | 0.000007 | 0.000001 | 0 | 0 |
| closing tables | 0.000009 | 0.000007 | 0.000000 | 0 | 0 |
| freeing items | 0.000047 | 0.000013 | 0.000035 | 0 | 0 |
| cleaning up | 0.000021 | 0.000014 | 0.000007 | 0 | 0 |
+----------------------+----------+----------+------------+--------------+---------------+ |
不使用索引的情况
+----------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+----------------------+----------+----------+------------+--------------+---------------+
| starting | 0.000094 | 0.000085 | 0.000008 | 0 | 0 |
| checking permissions | 0.000010 | 0.000008 | 0.000003 | 0 | 0 |
| Opening tables | 0.000023 | 0.000022 | 0.000001 | 0 | 0 |
| init | 0.000040 | 0.000038 | 0.000002 | 0 | 0 |
| System lock | 0.000011 | 0.000009 | 0.000002 | 0 | 0 |
| optimizing | 0.000012 | 0.000010 | 0.000001 | 0 | 0 |
| statistics | 0.000123 | 0.000109 | 0.000015 | 0 | 0 |
| preparing | 0.000017 | 0.000014 | 0.000003 | 0 | 0 |
| executing | 0.000003 | 0.000002 | 0.000001 | 0 | 0 |
| Sending data | 0.152585 | 0.142192 | 0.007219 | 0 | 0 |
| end | 0.000016 | 0.000004 | 0.000005 | 0 | 0 |
| query end | 0.000008 | 0.000007 | 0.000001 | 0 | 0 |
| closing tables | 0.000010 | 0.000010 | 0.000001 | 0 | 0 |
| freeing items | 0.000019 | 0.000010 | 0.000009 | 0 | 0 |
| cleaning up | 0.000034 | 0.000015 | 0.000019 | 0 | 0 |
+----------------------+----------+----------+------------+--------------+---------------+ |
使用索引的情况
从上面的执行计划可以看出,无论是是否使用索引,两次查询的耗时主要都在Sending Data上,这里Sending Data其实就是指MySQL服务器从磁盘上读取数据的耗时。对于上述查询,其实我们知道不使用索引的时候使用的是全表扫描,而使用索引的时候是索引过滤之后的数据扫描,并且由于MySQL的插件式存储引擎结构,其暂时是无法将where条件push down到存储引擎(如InnoDb)中进行数据扫描的,也就是说对于不使用索引的情况,MySQL是将数据从磁盘上读取到服务器层,然后依次扫描每条数据是否符合where条件,这也就是为什么不使用索引时其Sending Data如此之高的原因。对于使用索引的查询,从前面的二级索引结构图其实我们就已经知道,索引就是将字段数据去重分组之后的一个结构,并且叶节点上保存有所有相同数据的id,这样在使用first_name索引的时候,MySQL就可以过滤掉大部分数据,而直接从叶节点上获取符合条件的数据的id,这样从磁盘上读取的数据量将大大减少,这也就是为什么使用索引能够大幅提升效率的原因。
2.1.2 聚簇索引在索引结构一节我们讲了MySQL的聚簇索引的结构,也讲解了MySQL聚簇索引的生成方式,这里其实我们需要考虑的是两个问题:
- 如何使用聚簇索引提升查询效率;
- 如何自定义聚簇索引,及其优缺点;
对于第一条,我们知道,聚簇索引最大的优点在于磁盘数据的存储顺序是按照聚簇索引的顺序组织的,并且由于磁盘驱动器在驱动磁头读取数据的时候,其是会顺序预读下一个数据页的数据的(比如磁头正在读取当前数据页的数据时其同时也会将紧邻的下一个数据页的数据读取到磁盘缓存中),那么如果我们查询的数据正好与磁盘数据的顺序一致时查询效率将得到大幅度提升。这里我们可以考虑一种情况,比如对于一个user表和一个message表,它们是一对多的关系,如果message表的数据能够按照其user_id字段聚簇,那么当查询一个user及其发送的消息时,查询效率将非常的高。另一种常见的聚簇索引用法就是在查询一系列的id数据的时候,MySQL会对这些id进行排序,这样更有利于顺序扫描数据,这也就是为什么我们使用in (id, id,…)的时候,无论in列表中顺序如何,最后得到的数据的顺序都是以id的顺序组织的(这一点感觉上像一个bug,但是理解了原因之后也情有可原)。
根据前面的讲解,我们知道,如果需要表数据按照我们指定的方式组织,那么就只能对该表建立唯一索引,并且该表不能含有主键字段,如下图所示为一个自定义的聚簇索引表数据:
+-------+---------+-----------+-----------------+----------+--------------+-------------+
| id | site_id | config_id | exclude_site_id | excluded | show_in_site | show_in_crm |
+-------+---------+-----------+-----------------+----------+--------------+-------------+
| 1 | -1 | 1 | 0 | 0 | 1 | 2 |
| 2 | -1 | 2 | 0 | 0 | 1 | 2 |
| 3 | -1 | 3 | 0 | 0 | 1 | 0 |
| 4 | -1 | 4 | 0 | 0 | 1 | 0 |
| 10 | -1 | 10 | 0 | 0 | 1 | 2 |
| 11 | -1 | 11 | 0 | 0 | 1 | 2 |
| 74601 | 60 | 1 | 0 | 0 | 1 | 2 |
| 74546 | 60 | 2 | 0 | 0 | 1 | 2 |
| 74592 | 60 | 21 | 0 | 0 | 1 | 3 |
| 74534 | 60 | 65 | 0 | 0 | 1 | 2 |
| 74513 | 79 | 71 | 0 | 1 | 1 | 1 |
+-------+---------+-----------+-----------------+----------+--------------+-------------+ |
上述数据建有唯一索引(site_id, config_id),并且id并不是主键,可以看到该表的数据并不是按照主键进行组织的,而是按照site_id和config_id的大小顺序依次组织的。
关于第二个问题,上面其实已经进行了解答,这里我们需要着重说明一下自定义聚簇索引的缺点,如下图所示为一个聚簇索引业结构的示意图:
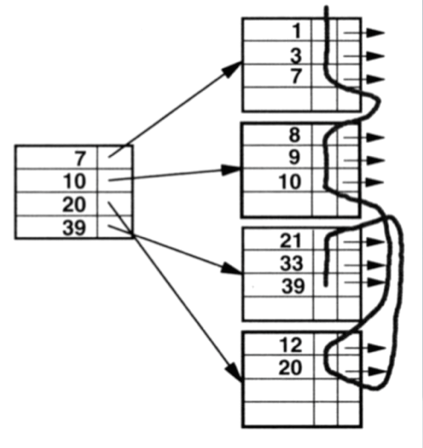
图中最开始是没有id为10,12和20的数据的,此时磁盘数据是按照id顺序组织的,当我们插入id为10的数据时,发现第二个叶结构上有多余的存储空间,因而10号数据插入到了该位置,然后插入id为12的数据时,发现已经没有多余的空间存储数据了,此时MySQL会顺序往下查找最近的可用地址空间,并创建一个新的页结构,将id为12的数据插入到该页中,并且为了维护B+树叶结构的顺序性,第二个数据页上指向下一个叶结构的指针将指向新创建的数据页,并且新数据页的指针将指向第三个数据页,上面的过程称为页分裂。页分裂造成的问题在于在进行磁盘数据顺序扫描时磁头先定位到第一个数据页,当读取完前两个数据页的数据时,磁头需要再次定位到新的数据页,读取完新数据页数据之后再定位回第三个数据页,这样磁头因为一次页分裂到额外多出了两次磁头的随机移动,这将对数据库的性能造成极大的影响。
从上面的分析可以看出,当数据按照我们所指定的方式聚集时,如果插入和更新数据比较频繁,那么将会导致大量的数据页分裂,会大大的影响数据库效率。MySQL默认使用主键作为聚簇索引,使用主键有一个非常大的优点在于主键都是自增的,每次新插入的数据只会在磁盘的尾部,也就不会出现页分裂的问题。对于更新数据,其造成的磁盘存储空间影响较小,因而造成页分裂可能性较小。从这一点看来,如非特别必要,尽量不使用自定义聚簇索引,并且使用数值型的id作为主键(使用UUID将导致新数据往磁盘数据中间插入)。另外,如果磁盘数据组织较为混乱,定期使用”optimize table table_name“命令进行数据重组将有利于查询效率的提升。
2.2 联合索引联合索引指的是多个字段按照一定顺序组织的索引。如下表所示为一个联合索引的示意图:
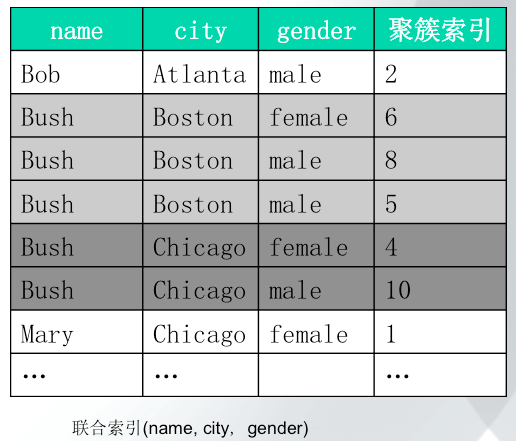
对于图中的索引(name, city, gender),其首先是按照name字段顺序组织的,当name字段的值相同时(如Bush),其按照city字段顺序组织,当city字段值相同时,其按照gender字段组织。根据前面的讲解,联合索引也是一种二级索引,因而其叶节点保存有聚簇索引的id值,如表中最后一列所示。
2.2.1 where条件联合所谓where条件联合指的是,对于where条件中的等值条件,其字段使用与联合索引的字段一致(顺序可以部一致),比如下面的查询:
**SQL语句: ** select * from actor where first_name='qWhNIZqxcbD' and last_name='rxkPMBqBvWnzbJe';
| 索引 | first_name | first_name, last_name |
|---|
| 耗时 | 0.24 | 0.01 |
可以看到,这里的联合索引(first_name, last_name)就是一个联合索引,其将该查询所使用的两个字段都覆盖了。通过与只使用单字段的索引比较,发现覆盖率越高的联合索引,其查询效率有一个质的提升。
2.2.2 order by条件联合order by联合指的是如果order by后面的字段是联合索引覆盖where条件之后的一个字段,由于索引已经处于有序状态,MySQL就会直接从索引上读取有序的数据,然后在磁盘上读取数据之后按照该顺序组织数据,从而减少了对磁盘数据进行排序的过程,如下表是磁盘有序结构的一个示意图:
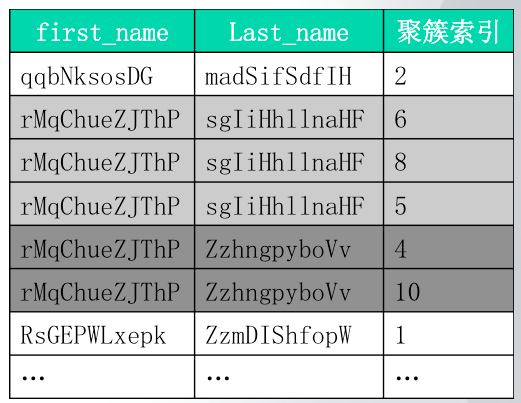
从表中可以看到,对于first_name相同的数据,其last_name的值是按照从小到大的顺序排列的。作为比较,我们可以对比如下SQL查询:
**SQL语句: ** select * from actor where first_name='rMqChueZJThP' order by last_name;
| | 索引 | first_name | first_name, last_name |
|---|
| 耗时 | 0.24 | 0.14 |
可以看到,如果只使用单列索引,其耗时比使用覆盖order by的联合索引耗时高一倍左右(实际使用时可能更高)。如下是这两个查询的执行耗时:
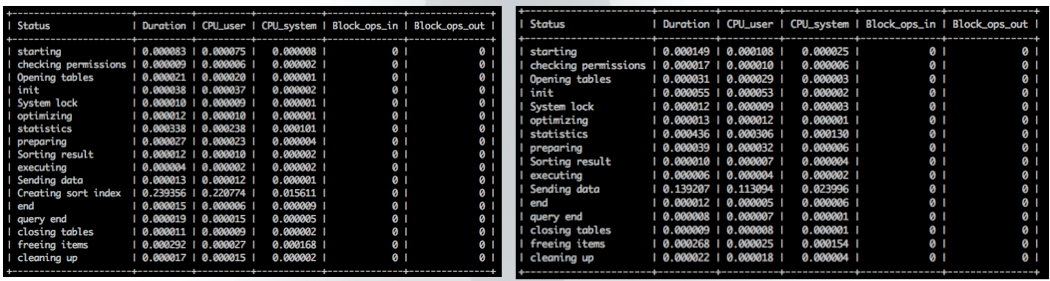
左图为未覆盖order by的查询,右图则为覆盖order by的查询。可以看到对于未覆盖order by的查询,其有一项Creating sort index,即为磁盘数据进行排序的耗时最高;对于覆盖order by的查询,其就不需要进行排序,而其耗时主要体现在从磁盘上拉取数据。
最后需要说明的是,类似于order by,如果查询中使用到了distinct和group by等查询,通过本小节中最开始的表格可以看出,如果distinct和group by的是覆盖where条件后索引的最后一个字段,那么其也是可以使用到索引的。
2.3 前缀索引MySQL的前缀索引可以分为三类:联合索引前缀,like前缀和字符串前缀。这三种前缀索引我们都会讲到其用法,并且会介绍其使用过程中需要注意的问题。对于字符串前缀索引,作为对比,这里会详细讲解哈希索引的用法。
2.3.1 联合索引前缀联合索引前缀指的是对于联合索引(A, B, C),那么如果查询的等值条件是(A),(A, B)或(A, B, C),那么这几个查询都是可以用到该联合索引的,该原则也称为“最左前缀匹配原则”。如下图所示为一个联合索引的表示意图:
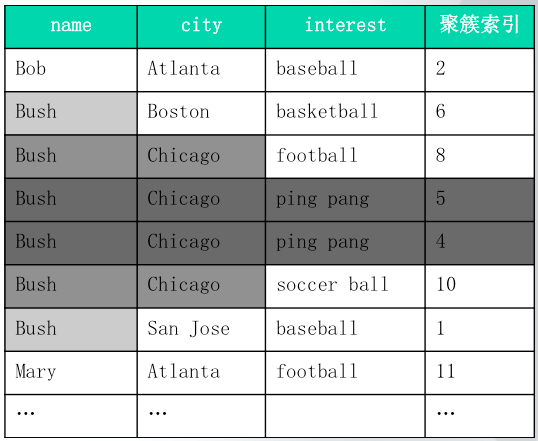
图中索引为(name, city, interest)三个字段联合的索引。从图中可以很明显的看出,如果查询条件为where name='Bush';那么就只需要根据B+树定位到name字段第一个Bush所在的值,然后顺序扫描后续数据,直到找到第一个不为Bush的数据即可,扫描过程中将该索引片的数据id记录下来,最后根据id查询聚簇索引获取结果集。同理对于查询条件为where name='Bush' and city='Chicago';的查询,MySQL可以根据联合索引直接定位到中间灰色部分的索引片,然后获取该索引片的数据id,最后根据id查询聚簇索引获取结果集。
根据上图和对索引定位过程的分析可以得出联合索引前缀的两个注意点:
- 无法跨越字段使用联合索引,如where name='Bush' and interest='baseball';。从上图可以看出,对于该查询,name字段是可以使用联合索引的第一个字段过滤大部分数据的,但是对于interest字段,其无法通过B+树的特性直接定位第三个字段的索引片数据,比如这里的baseball就分散在了第二条和第七条数据之中。不过这里需要说明的是,interest字段其实进行的是覆盖索引扫描,后续将讨论覆盖索引扫描的用法。
- 对于非等值条件,如>、<、!=等,联合索引前缀对于索引片的过滤只能到第一个使用非等值条件的字段为止,后续字段虽然在联合索引上也无法参与索引片的过滤。这里比如where name='Bush' and city>'Chicago' and interest='baseball';,对于该查询条件,首先可以根据name字段过滤索引片中第一个字段的非Bush的数据,然后根据联合索引的第二个字段定位到索引片的Chicago位置,由于其是非等值条件,这里MySQL就会从定位的Chicago往下顺序扫描,由于interest字段是可能分散在索引第三个字段的任何位置的,因而第三个字段无法参与索引片的过滤(同上一注意点一样,这里interest是参与的覆盖扫描)。
**SQL语句: ** select * from actor where first_name='rMqChueZJThP';
| 索引 | 无索引 | first_name, last_name |
|---|
| 耗时 | 6.34 | 0.13 |
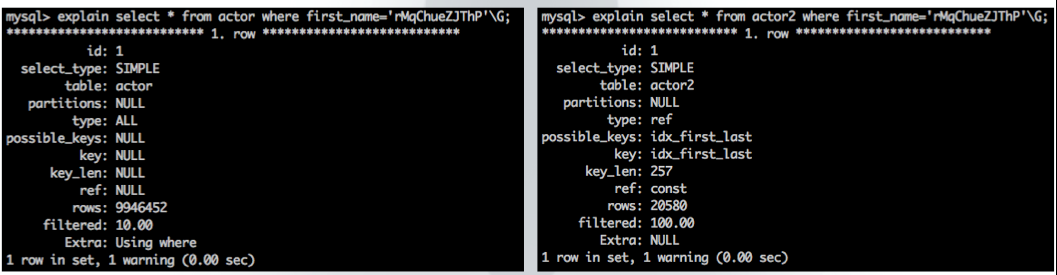
上述查询只使用到了first_name一个字段,但是表上建有(first_name, last_name)的联合索引,可以看到使用联合索引前缀的查询几乎和使用单列索引查询的效率一样高,如下是该查询的执行计划,可以看到没有联合索引时使用的是全表扫描,有联合索引时使用的是该联合索引:
2.3.2 like前缀对于like前缀,其是指在使用like查询时,如果使用的表达式为first_name like 'rMq%';那么其是可以用到first_name字段的索引的。但是对于first_name like '%Chu%';,其就无法使用first_name的索引。
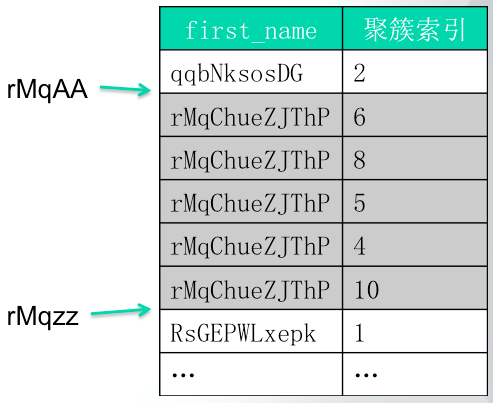
这里需要说明的是,对于like前缀,MySQL底层实际上是使用了一个补全策略来使用索引的,比如这里first_name like 'rMq%';,MySQL会将其补全为两条数据:rMqAAAAA和rMqzzzzz,后面补全部分的长度为当前字段的最大长度。在使用索引查询时,MySQL就使用这两条数据进行索引定位,最后需要的结果集就是这两个定位点的中间部分的数据。如下是使用like前缀的一个示意图:
**SQL语句: ** select sql_no_cache * from actor where first_name like 'rMq%';
| 索引 | 无索引 | first_name |
|---|
| 耗时 | 7.23 | 0.50 |
可以看到,对于like前缀查询,使用索引与不使用索引差别可达到几百个数量级。如下是使用索引的一个执行计划:
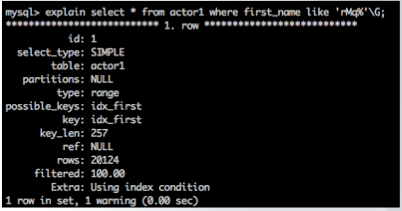
2.3.3 字符串前缀字符串前缀索引指的是只取字符串前几个字符建立的索引。在进行查询时,如果一个字段值较长,那么为其建立索引的成本将非常高,并且查询效率也比较低,字符串前缀索引就是为了解决这一问题而存在的。字符串前缀索引主要应用在两个方面:
- 字段前缀部分的选择性比较高;
- 字段整体的选择性不太大(如果字段整体选择性比较大则可以使用哈希索引)。
如图所示为为first_name字段建立字符串前缀索引的示意图:
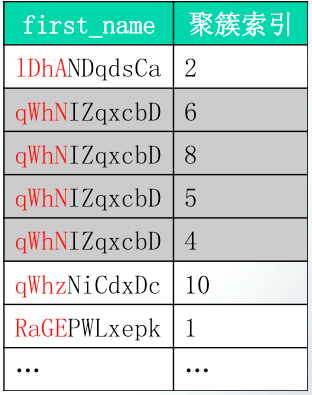
图中为first_name字段建立了长度为4的前缀索引,可以看到,如果查询使用的是where first_name='qWhNIZqxcbD';,那么MySQL首先会截取等值条件的前四个字符,然后将其与字符串前缀索引进行比较,从而定位到前缀为"qWhN"的索引片,然后获取该索引片对应的磁盘数据,最后将获取的磁盘数据的first_name字段与查询的等值条件的值进行比较,从而得到结果集。
字符串前缀索引最需要注意的一个问题是如何选择前缀的长度,长度选择合适时,前缀索引的过滤性将和对整个字段建立索引的选择性几乎相等。这里我们就需要用到前面讲解的关于字段选择性的概念,即字段选择性为对该字段分组之后,数据量最大的组的数据量占总数据量的比例。这里选择前缀长度时,可以理解为,前缀的选择性为按照前缀分组之后,数据量最大的组占总数据量的比例。如下表所示为计算前缀长度的SQL公式:
| SQL语句 | 前缀长度 |
|---|
| select count(*) as cnt, first_name as perf from actor group by perf order by cnt desc limit 10; | 0 | | select count(*) as cnt, left(first_name, 2) as perf from actor group by perf order by cnt desc limit 10; | 2 | | select count(*) as cnt, left(first_name, 3) as perf from actor group by perf order by cnt desc limit 10; | 3 | | select count(*) as cnt, left(first_name, 4) as perf from actor group by perf order by cnt desc limit 10; | 4 |
上表中的第一个查询其实就是按照整个字段建立索引的选择性,后续查询就是按照前缀长度分别为2,3,4时数据的选择性。如下图所示为该前缀选择性查询的结果:
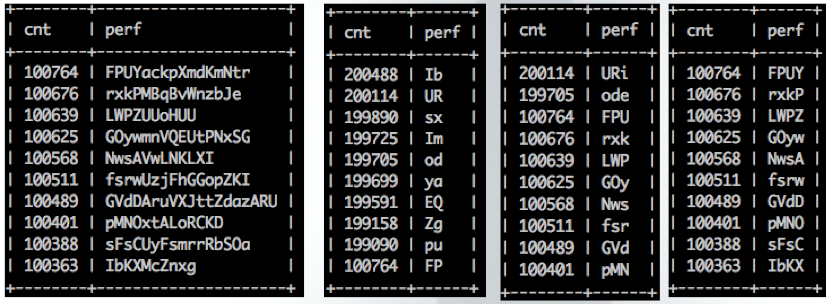
可以看到,对于全字段建立索引的选择性为1%;当前缀长度为2时选择性为2%;当前缀长度为3时少量前缀的选择性为2%,其余数据为1%,整体而言还是2%;当前缀长度为4时,选择性为10%,基本上和为全字段建立索引的选择性一样高。
关于前缀索引,这里需要说明的一点是,由于同一前缀对应的实际字段数据可能不同,因而前缀索引是无法像全字段索引那样进行order by,group by和distinct优化的,也无法进行非等值查询。如下SQL为建立前缀索引的SQL语句:
| ALTER TABLE actor ADD KEY (first_name(4)); |
**SQL语句: ** select * from actor3 where first_name='qWhNIZqxcbD';
| 索引类型 | 无索引 | first_name(4) |
|---|
| 耗时 | 6.05s | 0.15 |
2.3.4 哈希索引哈希索引同字符串前缀索引一样,都是为长字符串字段建立的索引,但哈希索引相对于字符串前缀索引解决了两个问题:
- 如果字符串字段的前缀部分选择性非常低,如URL,那么建立前缀索引成本将非常高;
- 当字符串字段整体的选择性非常高时,比如基本上每个值都是唯一的,此时无论是建立的全字段索引还是前缀索引其索引片都非常厚,对于内存的消耗比较大。
哈希索引的实现思路是,对一个字符串字段,为其每个值都计算一个哈希值,并且建立一个新字段用于存储这些哈希值,然后为这个新字段建立索引,并且为字符串字段建立插入和更新的触发器,用于更新哈希字段的值。在进行查询时,使用同一哈希算法计算查询的字符串的哈希值,使用该哈希值在哈希字段上进行查询,由于建立了索引,因而查询非常快,对于查询到的结果将查询的字符串与查询结果的字符串字段进行比较,从而得到最后的结果。这里由于新建立的哈希字段是整型的,因而其索引片非常小,并且由于字符串字段的选择性非常高,因而哈希字段的选择性相对非常高,因而总体而言,查询效率是非常高的。如下是针对actor表的email字段建立哈希索引的方式:
| 建立哈希字段 | ALTER TABLE actor ADD COLUMN hash_email BIGINT UNSIGNED NULL DEFAULT 0 COMMENT ’email字段的哈希值'; |
|---|
| 更新哈希字段 | UPDATE actor SEThash_email=crc32(email); | | 建立索引 | alter table actor add index `idx_hash_email` (hash_email); | | 建立插入触发器 | DELIMITER $
CREATE TRIGGER actor_hash_insert BEFORE INSERT ON `actor4` FOR EACH ROW BEGIN
SET NEW.hash_email=crc32(NEW.email);
END;
$ | | 建立更新触发器 | DELIMITER $
CREATE TRIGGER actor_hash_update BEFORE UPDATE ON `actor4` FOR EACH ROW BEGIN
SET NEW.hash_email=crc32(NEW.email);
END;
$ |
按照上述步骤即可建立一个哈希索引,对于哈希索引最后需要说明的是其查询方式,在进行查询时一定要带上查询的字符串与目标字段的等值比较,这是因为对于不同的数据,其哈希值可能是一样的,如:
select* from actor4 where hash_email=crc32('OZETIMfiqGCBAeEJuIp@yKIg.fnWxL')
and email='OZETIMfiqGCBAeEJuIp@yKIg.fnWxL'; |
2.4 覆盖索引覆盖索引指的是对于查询中使用的除去参与索引过滤扫描的所有字段将其加入到该查询所使用的索引尾部的索引。覆盖索引扫描的优点在于由于查询中所使用的所有字段都在同一索引的字段,因而在进行查询时只需要在索引中获取相关数据即可,而不需要回磁盘扫描相应的数据,从而避免了查询中最耗时的磁盘I/O读取。对于如下查询:
| select a, b, c from t where a='a' and b='b'; |
该查询中如果建立联合索引(a, b, c),那么这就是使用了覆盖扫描的索引,因为对于该查询,可以使用索引的前两个字段a和b根据where条件进行索引片的过滤,对过滤后的索引片直接在索引中读取a, b, c三个字段的值即可,而无需回表扫描。如下查询是一个索引覆盖扫描的实例:
**SQL语句: ** select first_name, last_name from actor where first_name='qWhNIZqxcbD';
| 索引 | first_name | first_name, last_name |
|---|
| 耗时 | 1.12 | 0.01 |
可以看到,如果只使用first_name索引,其需要回磁盘读取last_name的值,从而返回最终数据,而对于(first_name, last_name)的联合索引,其不需要回磁盘扫描,因而耗时不到10ms。
2.5 三星索引三星索引指的是对于一个查询,设立了三个通用的索引条件满足的条件,建立的索引对于特定的查询每满足一个条件就表示该索引得到一颗星,当该索引得到三颗星时就表示该索引对于该查询是一个三星索引。三星索引是对于特定查询的最优索引,建立三星索引的条件如下:
- 取出所有的等值谓词的列(WHERE COL=…)作为索引开头的列;
- 将order by中的列加入到索引中;
- 将查询语句中剩余的列加入到索引中,将易变得列放到最后以降低更新成本。
比如对于如下的查询,索引(first_name, last_name, email)就是一个三星索引:
SELECT
first_name,
last_name,
email
FROM actor5
WHERE first_name = 'hawIPYaXHTSKHlTstt'
ORDER BY last_name; |
仔细分析三星索引的创建过程可以发现如下规律:
- 覆盖等值谓词条件,如first_name,可以过滤大部分的索引片数据;
- 覆盖order by字段可以避免对结果集的排序,如last_name;
- 覆盖其余字段可以避免回磁盘读取数据,即使用了覆盖索引扫描,如email。
3. 不恰当的索引用法 3.1 无法使用索引的情形- 对索引字段使用MySQL函数(可以对等于号后的值使用,不能对字段使用)
| select * from actor where lower(first_name)='rmqchuezjthp’; |
正确做法:
| select * from actor where first_name='rMqChueZJThP'; |
- 隐式字符串转换(这里license字段为一个varchar类型字段)
| select * from actor where license=6535; |
正确做法:
| select * from actor where license='6535'; |
| select * from actor where hash_email + 2 = 4224712734; |
正确做法:
| select * from actor where hash_email = 4224712732; |
总结:从上述无法使用索引的情形可以看出,如果对索引字段进行了任何的表达式运算,那么其都会使索引功能失效,这是因为索引始终是一个B+树,使用其进行索引片过滤的时候是通过“二分查找”实现的,如果进行了计算,那么就无法使用“二分查找”功能,也就使得索引失效了。
3.2 困难谓词 3.2.1 不等式,如>,<,!=等| select A, B, C, D from TABLE where A=a and B>b and C>c; |
推荐索引:(A, B, C, D)或(A, C, B, D)
对于上述查询,如果B和C字段的选择性,哪一个高就将其放在索引字段的前面。对于索引(A, B, C, D),在查询时首先会根据字段A的等值条件和B的不等值条件进行索引片的过滤,然后扫描索引中B字段大于b的数据,在扫描过程中会判断获取到的数据是否满足C>c的条件,并且将符合条件的数据的D字段的值取出来,最后得到的结果集就是最终的结果集。该查询中A和B字段是参与了索引片的过滤的,而C和D字段则参与了索引覆盖扫描。
3.2.2 OR谓词| select A, B, C from TABLE where A>a or B>b; |
推荐索引(A)和(B)
对于OR条件查询,由于并不是满足其中一个条件即可,而是两个条件只要满足一个即可。这里推荐索引为建立两个单列索引(A)和(B),因为MySQL可以通过这两个索引进行“索引合并扫描”,也就是其首先会扫描索引A,获取其符合A>a条件的数据id,然后扫描索引B,获取其符合B>b的数据id,然后将两个扫描结果进行合并,最后通过合并的数据id在磁盘上读取数据。
对于OR谓词的索引合并扫描需要说明的是,如果需要合并的结果集非常大,或者是结果集中重复数据过多,那么进行结果集的合并将是一个非常耗时的操作,有时候效率还不及全表扫描。对于这个问题的另一个解决办法就是新建一个字段,取值1和0,标识其是否符合where条件,这样就只需要对该字段进行查询即可,也可以建立相关的索引。
3.2.3 IN谓词| select A, B, C from TABLE where A in (m, n, p) and B=b; |
推荐索引:(A, B)
这里IN谓词严格意义上讲不是一个困难谓词,放在这里是为了借用OR谓词的索引合并扫描进行说明。对于IN谓词后的列表,MySQL会循环列表中的数据,然后分别于后续索引字段联合,比如对于上述查询,其可以拆分为(A=m and B=b) union (A=n and B=b) union (A=p and B=b)。拆分之后MySQL会首先根据A=m and B=b扫描联合索引(A, B),获取结果集的id,然后根据A=n and B=b再次扫描该索引,依次循环,知道所有IN列表条件都扫描完成。由于IN列表条件是不重复的,因而最后扫描索引片也是不重复的,在进行结果集的合并的时候也就没有类似OR谓词的去重操作,因而查询效率非常的高。总结来说,IN谓词及其后续字段是可以使用到索引的。
4. 总结本文首先讲解了数据的存储方式和索引的结构,然后对各种创建索引的方式进行了深入的讲解,并且讲解了其中需要注意的点,最后我们介绍了一些使用索引时需要注意点和一些困难谓词。
----------------------------
原文链接:https://www.jianshu.com/p/6446c0118427
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-06-18 11:17:18 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用


