|
|
性能优化,是存储工程师们永远的追求,在我们看来,除了调整存储架构、优化IO路径,能对应用做出有针对性的优化,也是非常重要和有意义的事情,这意味着,除了要了解存储本身,还需要对上层应用或中间件有足够的认识。这次,我们就来看看 MySQL 的 IO 特点和存储针对 MySQL 的优化思路。
MySQL 架构组件说明
MySQL 及其延续的 MariaDB 是目前市场上最流行的关系型数据库管理系统,在很多应用场景中,MySQL 都是用户首选的 RDBMS(Relational Database Management System关系数据库管理系统)。
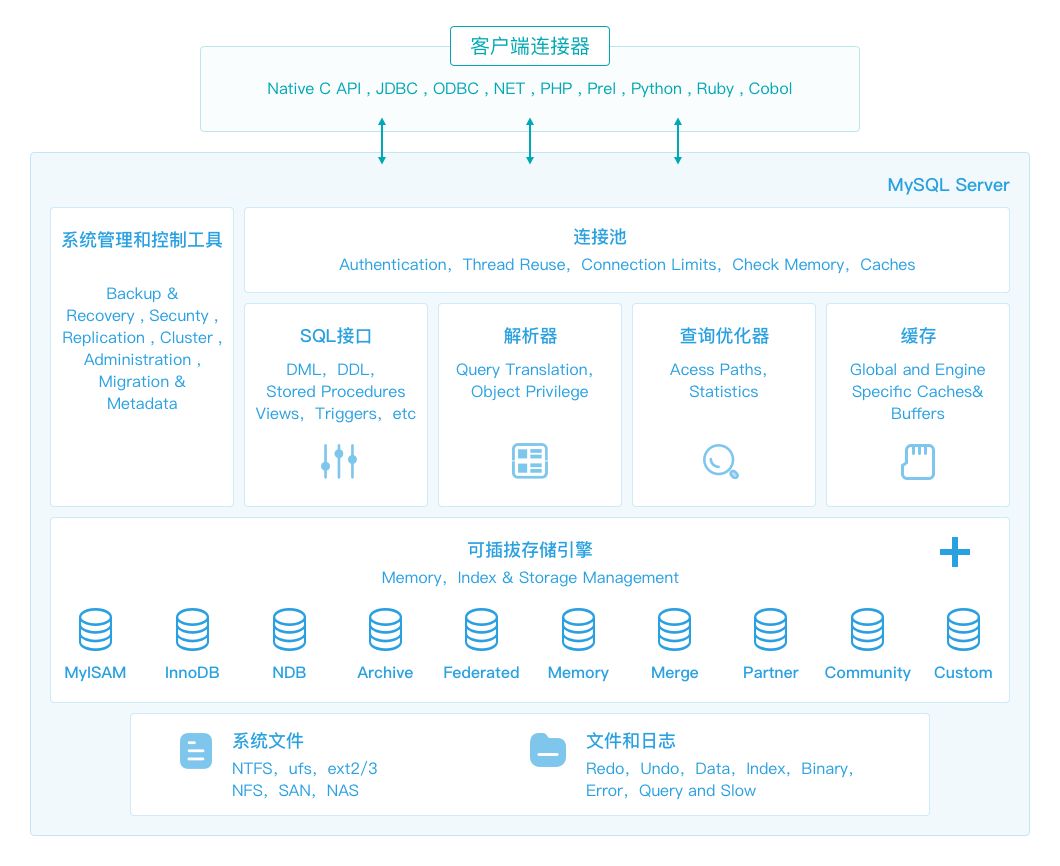
MySQL大致包括如下几大基础模块组件:
- MySQL客户端连接组件(Connectors)
- 系统管理和控制工具组件(Management Service & Utilities)
- 连接池组件(Connection Pool)
- SQL组件( SQL Interface)
- 解析器组件(Parser)
- 查询优化器组件(Optimizer)
- 缓存组件(Caches & Buffers)
- 存储引擎(Pluggable Storage Engines)
- 文件系统(File System)
InnoDB 存储引擎
存储引擎在 MySQL 的体系架构中位于第三层,负责对 MySQL 中的数据进行存储和提取,是与文件打交道的子系统,它是根据底层提供的文件访问层抽象接口定制的一种文件访问机制,这个机制就叫作 MySQL 存储引擎。从 MySQL 5.5 开始,默认采用 InnoDB 作为存储引擎。因此,优化底层存储对 MySQL 业务的的性能,就要从了解和分析存储引擎如何与底层的存储系统进行交互开始。
下图是官方的 InnoDB 引擎架构图,InnoDB 存储引擎主要分为内存结构和磁盘结构两大部分。
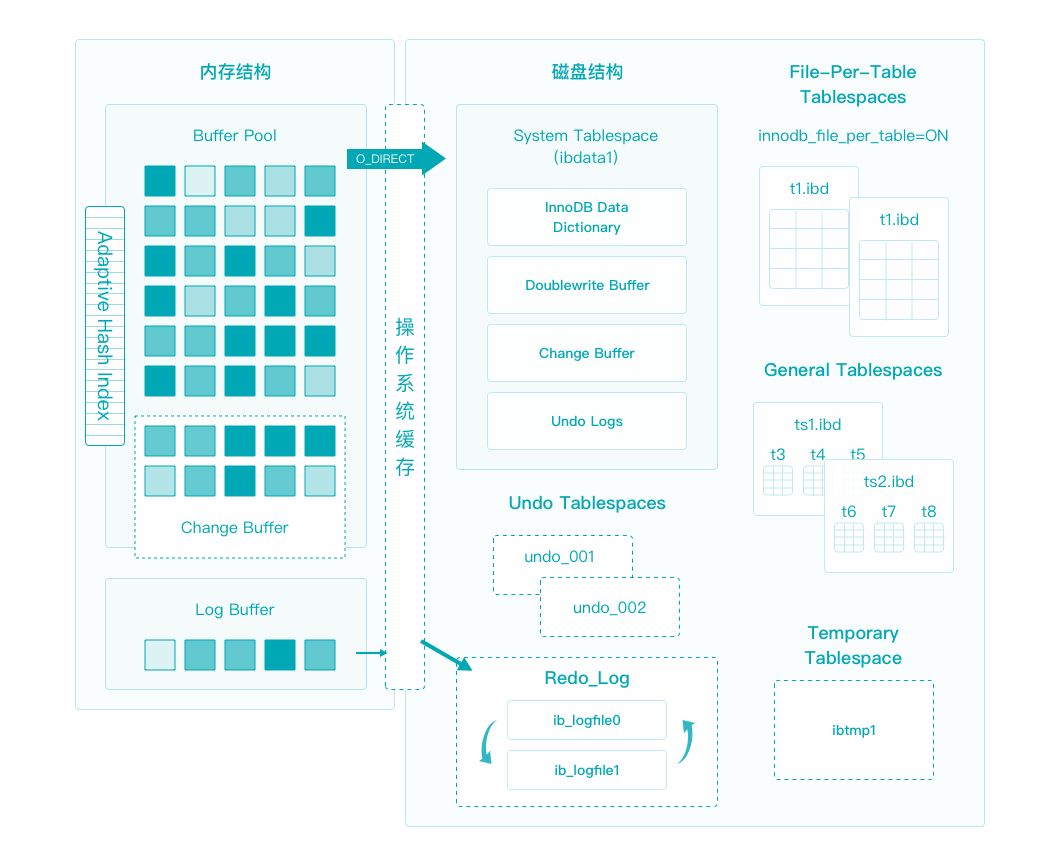
InnoDB 磁盘主要包含 Tablespaces、InnoDB Data Dictionary、Doublewrite Buffer、Redo Log和 Undo Logs。Redo Log和 Binlog 是 MySQL 日志系统中非常重要的两种机制,本文主要谈一下对 Redo Log 和 Binlog 进行的分析及存储优化。
MySQL IO 模型和特点
MySQL 写数据过程中,有两个重要的日志文件,Redo Log 和 Binlog。Redo Log 记录了对InnoDB 存储引擎的事务日志,Redo Log 的写 IO 是固定文件范围内的循环写,IO 大小是 512 字节对齐(存在部分 offset 相等,执行的是覆盖写)。Binlog记录了对 MySQL 数据库执行更改的所有操作,Binlog的写 IO 是文件 append 写,IO 不对齐。MySQL 写请求时的存储行为:单线程执行 MySQL insert 写数据时,一个 insert 对应一个write 操作;多线程并发执行 insert,MySQL 会将部分 IO 合并,然后下发到文件系统(如果是使用远程文件系统,这个 IO 会被远程文件系统的客户端捕获,例如 YRCloudFile 的客户端),调用 write 请求写入到 /MySQL/ib_logfile 文件中。一次 write IO 之后,立即调用fsync。
在开启 Binlog 的场景下,写完一次 Redo Log 后会再写一次 Binlog,然后对 Binlog 做一次 fsync,以保证数据安全。当日志数据写入一定量之后,MySQL 后台另外一个线程会将所有的写入,以每个 IO 16K 的大小进行整理,并以 aio 方式写入到 /MySQL/ibdata 表文件中。
MySQL读请求时的存储行为:MySQL读时,会从MySQL的缓存中查找数据,缓存命中,就不会实际下发 read IO 到底层文件系统中。
YRCloudFile 针对 MySQL 日志 IO 行为优化
由于 Redo Log 、Binlog 都是一次 IO 写入伴随着一次 fsync,而根据实际测试发现,fsync 对于存储的开销比较大。所以,对 MySQL 性能的优化,我们需要在完全确保这两个日志文件数据安全的前提下调整这两个 Log的 IO 行为。
在 YRCloudFile 数据服务端,Redo Log 写文件以 direct 方式写入,写入之后我们自动做一次 fsync。Binlog 由于 IO 不对齐,不可以采用 direct 方式写,需要先写入系统缓存,然后做一次 fsync。这样,其实客户端就不用再对 Redo Log 和 Binlog 文件做 remote_fsync 了,省去了客户端调用 fsync 的开销影响。下面是一组实测的数据对比:
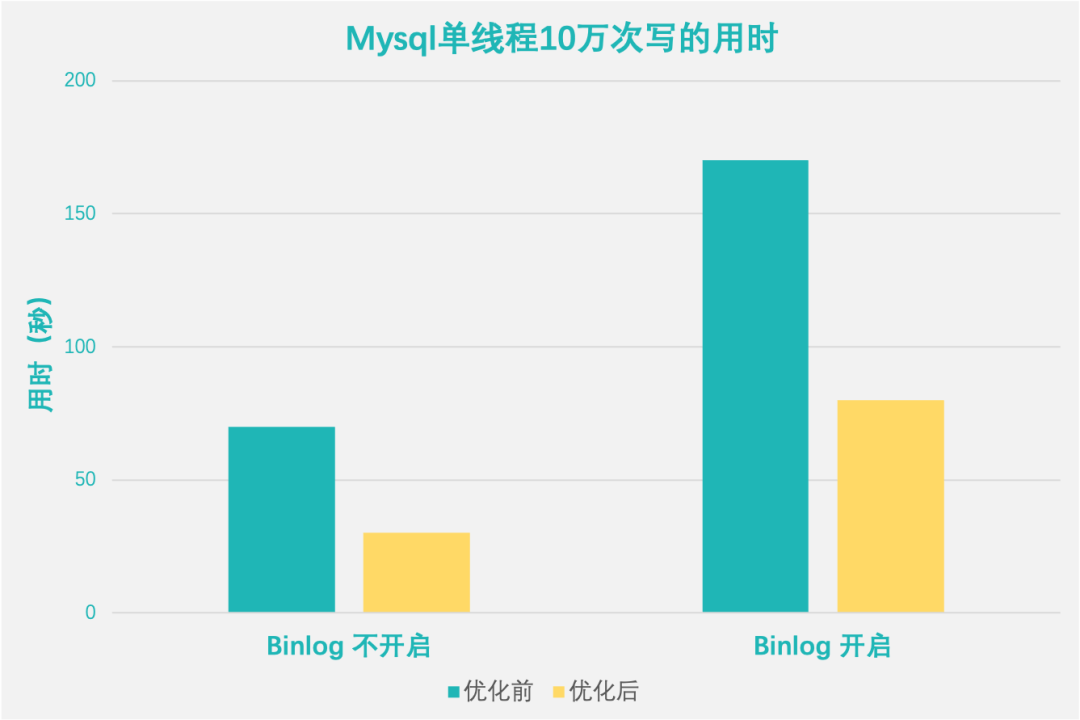
从实测结果上,我们可以看出,在调整了 YRCloudFile 后端针对性的写逻辑后后,MySQL 单线程写入的性能得到了翻倍的提升。
存储的研发工程师们就是这样,不但要掌握存储的核心技能,还要关注和分析上层应用的业务行为,才能对应用做出针对性的优化。以后,我们还会带来更多面向应用的优化过程和分析,大家敬请期待。
----------------------------
原文链接:https://blog.51cto.com/u_15191752/2908135
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2021-06-21 00:01:48 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用


