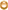|
|
1. 索引是什么东西?
索引就是一个数据结构,我们把表中的记录用一个适合高效查找的数据结构来表示,目的就是让查询变得更高效。
2. 它到底怎么运作的?
这个问题就说来话长了,且听我慢慢道来:
在mysql中使用最广泛的数据引擎是InnoDB 引擎,它里面用的是 B+ 树索引。
我们重点分析一下这个索引的原理:
要想理解B+树索引要先从 二叉查找树,平衡二叉树和 B 树说起因为B+树索引就是由他们演化而来:
什么是二叉查找树?
满足这样条件的就叫二叉查找树:
每个节点左边节点的值都小于该节点,右边节点的值都大于该节点,没有值相等的节点,最顶端的节点也就是“45”被称为根节点。
二叉查找树的查找过程:
若根结点的值等于查找的值,成功,
否则,若小于根结点的值,递归查左子树(也就是根节点左边的所有节点形成的树)
若大于根结点的值,递归查右子树(也就是根节点右边所有节点形成的树)。
假设用二叉查找树创建book表的索引:
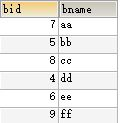
索引如下:
图一
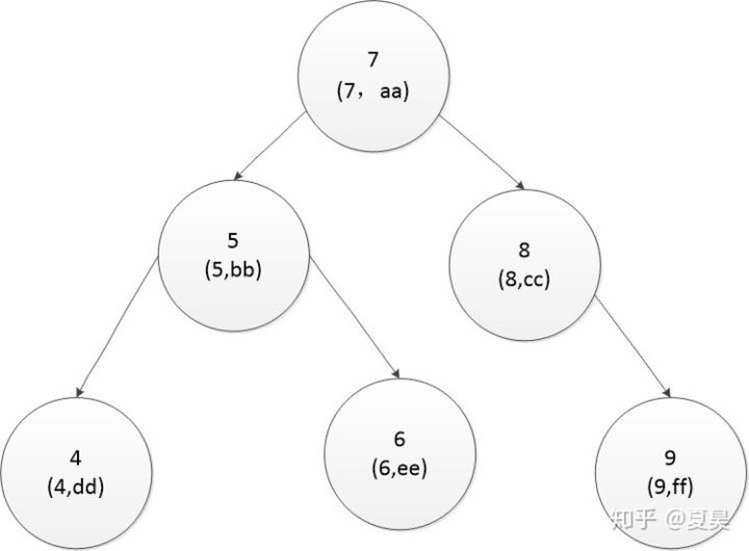
此处的bid为主键,每个节点存储了主键的值和该条记录的内容。
如果我要查找bid为6的图书的信息,则先用6和根节点的主键值7比较发现比7小,
然后6再和7左边的节点5比较发现比5大找到5右边的节点6,找到了,取出6对应的记录行的值ee.
总共经历了3次比较,如果扫描全表需要经过5次比较。
什么是平衡二叉树?
如果索引是这样:
图二
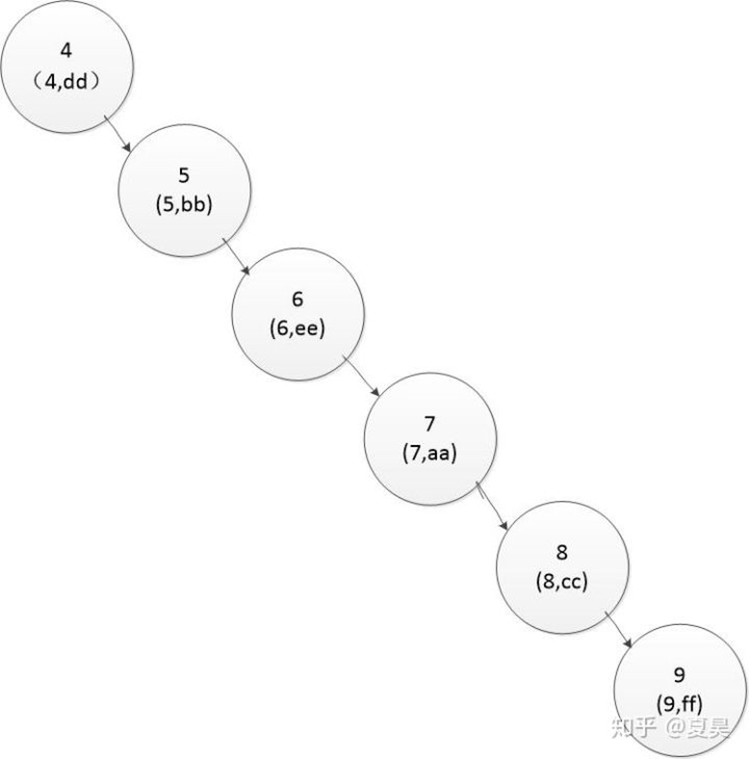
想要找到主键键值为9的记录就需要6次比较,索引的优势完全体现不出来。
为什么会这样?原因就在于这棵树太高了,如果能想办法把它变得矮一点,胖一点就完美了。于是平衡二叉树闪亮登场:
平衡二叉树首先也是一个二叉树,需要满足二叉树的所有条件,然后有所改进,规定了左右子树的高度差不能超过1,如果插入数据导致高度差超过了1则自动进行调整,回复到平衡状态。这也是平衡二叉树名字的由来。
图一就是一颗平衡二叉树,图二根节点的左子树高度为0,右子树高度为5,高度差是5超过了1所以不是一颗平衡二叉树。
平衡二叉树查找效率要高于二叉树。
什么是B树?
由前面的推导我们可以看出要想查找,比较的次数最少,必须想办法降低树形结构的高度,不管是二叉树还是平衡二叉树,每个节点最多只能有两个子节点,这就注定了它的高度受限于子节点的个数,于是B树横空出世.
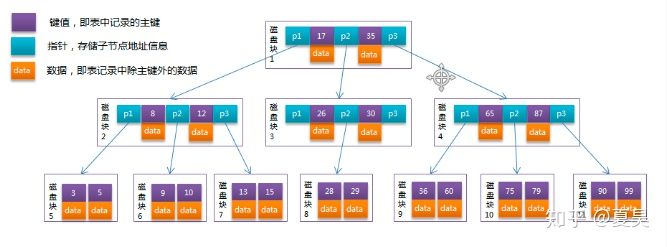
从上图可以看到B树的节点可以不止两个子节点,这样的好处就是树可以变得又矮又胖,矮胖的树是索引的最爱,用它做索引可以降低磁盘的IO.
B 树中的每个节点根据实际情况可以包含大量的键值,数据和指针,上图所示为一个3阶的B树:
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的键值和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个键值划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,键值为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的键值是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B树查找效率的决定因素。
什么是B+树?
想想还有没有可能进一步优化,在B树中每个节点的内容由三部分组成:键值,指针,数据,而磁盘块的容量是有限的,并不是每次读取磁盘块都会取出里面的数据,只是在最后一次读取的时候才会取出里面的数据,能不能将数据只存储在叶子节点里面,非叶子节点只存储键值和指针呢?这样就能最大化的利用磁盘块空间,一个磁盘块也就能存更多的东西了,没错,B+树就是这么干的
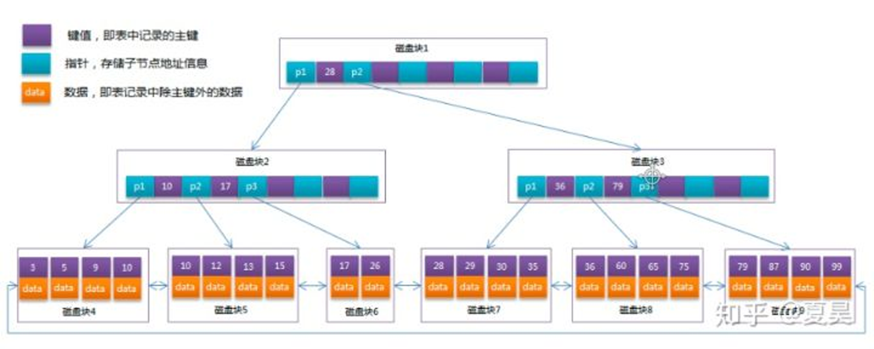
假设在非叶子节点不存数据以后每个节点可以存储4个键值和指针,就变成了上图的B+树
B+Tree 相对于B-Tree有几点不同:
1. 非叶子节点只存储键值和指针。
2. 所有叶子节点之间都有一个链指针。
3. 数据记录都存放在叶子节点中。
在B+树上有两个头指针,一个头指针指向根节点,可以进行从根节点开始的查找,还有一个头指针指向键值最小的叶子节点,因为键值是按顺序排列的所以可以进行键值的范围查找。
在B+树中由于一个节点存储了更多的键值和指针,所以同样的多的内容可以降低树的高度,减少磁盘io次数,从而提高效率。
----------------------------
原文链接:https://blog.51cto.com/11583017/2468495
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-01-29 18:04:50 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用