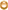|
|
优化前 我们有一个定时任务,循环从数据库捞一批数据(业务上称这它为资源)出来处理,一次捞取1000条。处理流程较长,需要查询这批资源的各种关联信息,还要根据组织查询一批用户,根据特定的算法计算出每一条资源需要分发给哪个用户,最后执行分发,然后把分发结果落库,并发送钉钉通知。
任务的性能很差。仅仅1000条资源,就需要十多分钟才能分发完。目前的业务一般一天会分发2w条资源左右,有时候会分发几个小时才发完,非常不合理。
定位耗时环节 于是我们打算优化一下这个任务。那首先要做的是理清楚代码逻辑和架构,第二步就是定位程序中比较耗时的环节,好做针对性的优化。
使用Arthas的
命令可以查询某个方法的内部调用路径,并输出方法路径上的每个节点耗时。非常适合于用来定位任务的耗时环节。
尽量不要在生产环境的机器上执行trace命令,尤其是调用量较大的业务。
# 使用trace
trace demo.MathGame run
# 过滤掉jdk的函数
trace -j demo.MathGame run
# 根据调用耗时过滤
trace demo.MathGame run '#cost > 10' |
使用trace命令后,可以明显发现一些环节调用耗时不太正常,比如每个资源都会去捞取某些组织相应的用户列表,大概几千个用户,然后再遍历查询和组装每个用户的信息,这一套下来就差不多3秒钟了。

优化 在分析代码过程中,发现还有其它一些不合理的设计,后面对这些不合理的地方都进行了一定程度的优化。
使用缓存避免重复查询 我们发现,在组装用户信息的时候耗时比较严重,因为要去请求其它服务,然后还要去数据库拿数据。
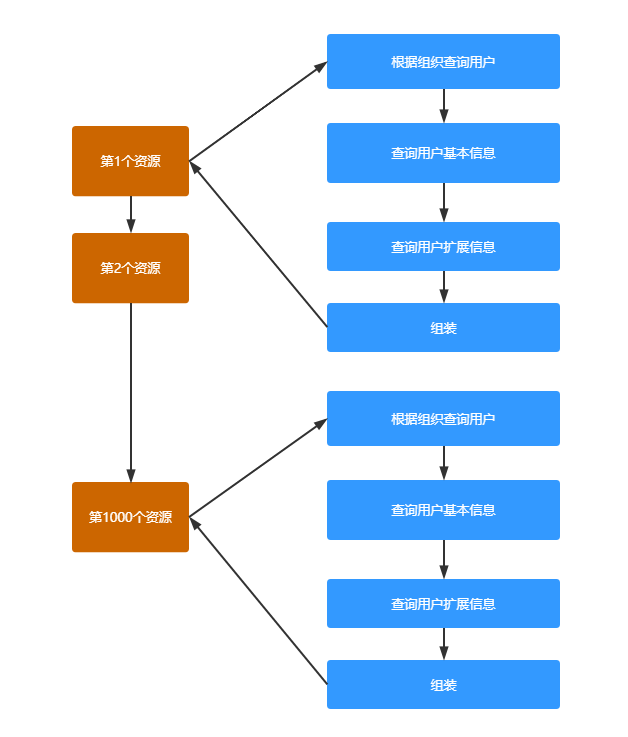
但每个资源都要去做同样的事情:拿某几个组织下所有用户的信息,产生了大量的重复查询。
很明显,我们只需要第一次去查询就够了,查询出来后,放入到缓存里面,后续资源只需要去缓存里面取就行了。
这里的缓存我们使用的是Redis,而不是内存缓存。因为我们在分发完成后会对用户信息做修改,而后面打算把它做成分布式的,多台机器共享用户信息,所以没有用内存缓存。
串行改并行 在代码分析过程中,发现很多是通过循环串行去做的。比如查询用户的详细信息并拼装,还有分发资源的时候、以及一些计算的时候。
虽然程序中在某些环节使用了多线程,但还是有些比较耗时的地方是串行的,导致整个程序比较慢。我们的机器是4核的,所以可以重复利用多核的优势,使用多线程去做一些性能上的优化。
主要有两种场景的串行可以改成并行:
循环 对于一个集合,我们下意识地通常会使用for循环去遍历它,做一些事情:
List<Result> list = new LinkedList<>();
for(Resource resource : resources) {
User user = computeTarget(resource, users);
Result result = distribute(resource, user);
list.add(result);
} |
如果循环体里面的操作比较耗时,这种串行循环就是比较慢的。这种情况可以简单地使用Java 8的并行Stream(其底层是Fork/Join框架),来达到一个并行的效果。不过如果改成了并行以后,需要注意线程安全的问题,比如上述代码,我们会把结果加到一个List里面,原本串行的时候使用一个简单的ArrayList就行了。但我们常用的ArrayList和LinkedList都不是线程安全的。所以这里需要替换成一个高性能的线程安全的List:
List<Result> list = new CopyOnWriteArrayList<>();
resources.parallelStream().forEach(resource -> {
User user = computeTarget(resource, users);
Result result = distribute(resource, user);
list.add(result);
}) |
使用Java 8的并行Stream有一个问题,就是一个程序内部是用的同一个Fork/Join线程池,用户不好去调参。所以我们可以使用自定义的线程池来实现串行改并行的需求:
List<Result> list = new CopyOnWriteArrayList<>();
List<Callable<Void>> callables = resources.stream()
.map(s -> (Callable<Void>) () -> {
User user = computeTarget(resource, users);
Result result = distribute(resource, user);
list.add(result);
return null;
}).collect(Collectors.toList());
executorService.invokeAll(callables, 20, TimeUnit.SECONDS); |
没有前后关系的耗时操作 另一种典型的串行方式就是在代码中要调用多个API,但它们可能彼此并不需要有前后关系。比如我们可能要调用多个服务或者查询数据库,来最后拼装成一个东西,但每个操作要拼装的属性彼此是独立的,这个时候我们也可以改成并行的。
举个例子,改造前的代码可能是这样:
// 串行方式:
OneDTO one = oneService.get();
TwoDTO two = twoService.get();
ThreeDTO three = threeService.get();
nextHandle(new Result(one, two, three)); |
我们使用JDK自带的神器CompletableFuture来简单改造一下:
// 并行方式:
Result result = new Result();
CompletableFuture oneFuture = CompletableFuture.runAsync(
() -> result.setOne(oneService.get()));
CompletableFuture twoFuture = CompletableFuture.runAsync(
() -> result.setTwo(twoService.get()));
CompletableFuture threeFuture = CompletableFuture.runAsync(
() -> result.setThree(threeService.get()));
CompletableFuture.allOf(oneFuture, twoFuture, threeFuture)
.thenRun( () -> nextHandle(result)) |
同步改异步 同步改成异步有时候能够带来巨大的性能提升。一个操作不管你在同步的时候会消耗多少时间,一旦我改成了异步,那对于当前的程序来说,它就是无限趋近于0。
什么情况下同步可以改成异步?这个其实是业务场景决定的。在我这个场景,资源分发完成后的一些后置操作其实是可以直接改成异步的,比如:通知用户、分发结果写入数据库等。
同步改异步也非常简单,丢到线程池里面去做就完事了。
executorService.submit(() -> {
someAction();
}); |
单机改分布式 前面介绍了串行改并行。比如我们1000个资源,如果一个执行1秒钟,那串行是不是就是1000秒。如果用10个线程去并行,就编程了100秒。
线程数量是收到机器限制的,不可能扩增到很大。但机器可以,并且多个机器和每台机器上的线程数量是可以相乘的。
我们这个服务假设有10台机器,然后再每台机器用10个线程去并行,那1000个资源分散到10台机器上去处理,只需要10秒。如果我们扩展到了100台机器,它只需要1秒。
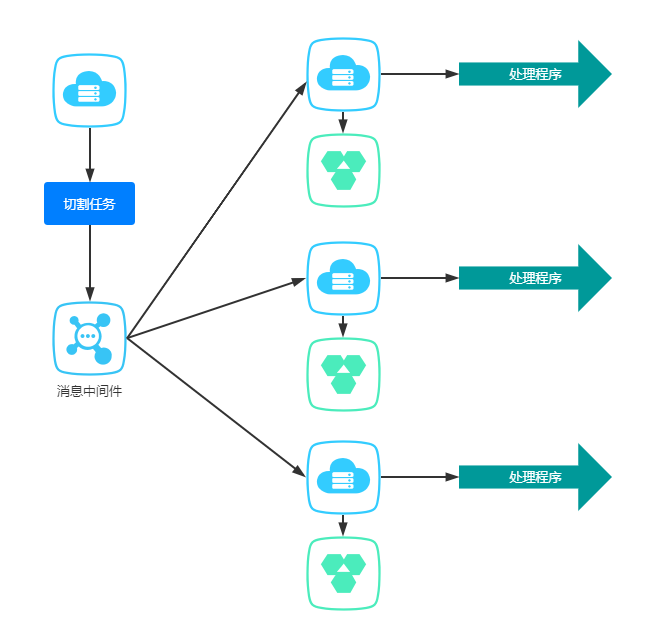
我们来看看单机下的运行模式:我们从库里面捞1000个资源,然后自己处理了,其它机器比较空闲。
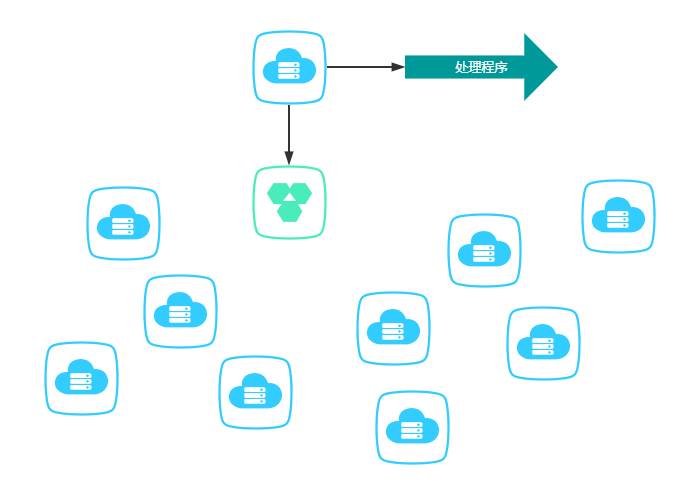
单机改分布式其实很简单,我们只需要在入口处去改造就行了。捞取资源后,通过消息发出去,然后其它机器接收消息,获取资源开始处理。
或者发送端不捞取资源,直接切割好每个消息的start和offset,通过消息发送出去,让接收端去捞资源。
----------------------------
原文链接:https://www.jianshu.com/p/e49313d0b553
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2021-01-12 10:10:44 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用