Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。 RDD持久化使用场景 1、第一次加载大量的数据到RDD中 RDD持久化策略 持久化策略的选择 ? 默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。 测试案例 测试代码如下: package cn.xpleaf.bigdata.spark.scala.core.p3import org.apache.log4j.{Level, Logger}import org.apache.spark.storage.StorageLevelimport org.apache.spark.{SparkConf, SparkContext}/** new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())new SparkContext(conf)// linesRDD.cache() // linesRDD.persist(StorageLevel.MEMORY_ONLY) // 执行第一次RDD的计算 val retRDD = linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)// retRDD.cache() // retRDD.persist(StorageLevel.DISK_ONLY) retRDD.count()// 执行第二次RDD的计算 start = System.currentTimeMillis()// linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).count() retRDD.count()// 持久化使用结束之后,要想卸载数据 // linesRDD.unpersist()
共享变量 提供了两种有限类型的共享变量,广播变量和累加器。 package cn.xpleaf.bigdata.spark.scala.core.p3import org.apache.log4j.{Level, Logger}import org.apache.spark.{SparkConf, SparkContext}/** new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())new SparkContext(conf)
num = 0
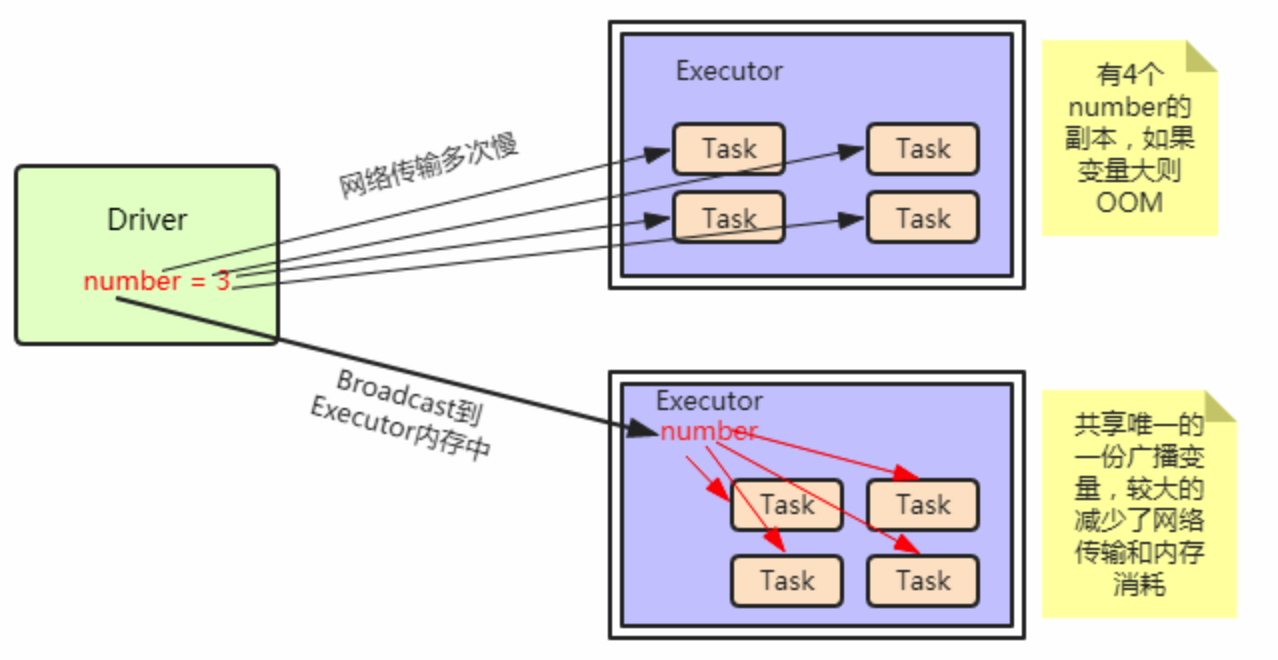
广播变量 Spark的另一种共享变量是广播变量。通常情况下,当一个RDD的很多操作都需要使用driver中定义的变量时,每次操作,driver都要把变量发送给worker节点一次,如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低。使用广播变量可以使程序高效地将一个很大的只读数据发送给多个worker节点,而且对每个worker节点只需要传输一次,每次操作时executor可以直接获取本地保存的数据副本,不需要多次传输。 这样理解, 一个worker中的executor,有5个task运行,假如5个task都需要这从份共享数据,就需要向5个task都传递这一份数据,那就十分浪费网络资源和内存资源了。使用了广播变量后,只需要向该worker传递一次就可以了。 创建并使用广播变量的过程如下: package cn.xpleaf.bigdata.spark.scala.core.p3import org.apache.log4j.{Level, Logger}import org.apache.spark.broadcast.Broadcastimport org.apache.spark.{SparkConf, SparkContext}/** new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())new SparkContext(conf)// "001,刘向前,18" val gender = info.substring(info.lastIndexOf(",") + 1)
001,刘向前,18,女
package cn.xpleaf.spark.p5import org.apache.spark.broadcast.Broadcastimport org.apache.spark.{SparkConf, SparkContext}/** new SparkConf()new SparkContext(conf)case (sex, name) =>
(女,Amy)
当然这个案例只是演示一下代码的使用,并不能看出其运行的机制。 累加器 Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能。但是确给我们提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。 package cn.xpleaf.bigdata.spark.scala.core.p3import org.apache.log4j.{Level, Logger}import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/** new SparkConf().setMaster("local[2]").setAppName(_01SparkPersistOps.getClass.getSimpleName())new SparkContext(conf)// 要对这些变量都*7,同时统计能够被3整除的数字的个数 val list = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13)if (num % 3 == 0) {// 下面这种操作又执行了一次RDD计算,所以可以考虑上面的方案,减少一次RDD的计算 // val ret = mapRDD.filter(num => num % 3 == 0).count() mapRDD.foreach(println)
49
package cn.xpleaf.spark.p5import org.apache.spark.{SparkConf, SparkContext}/** new SparkConf()new SparkContext(conf)// 累加器,用来统计rdd中的偶数 val counterAcc = sc.accumulator[Int](0)// 普通的counter变量 var counter = 0// 需要触发transformation的执行 rdd.map {if (num % 2 == 0) {// 累加器和普通counter变量都加1 counterAcc.add(1)
counterAcc: 3, counter: 0
https://blog.51cto.com/xpleaf/2108614 www.javathinker.net
[这个贴子最后由 flybird 在 2020-01-21 21:51:55 重新编辑]
网站系统异常
系统异常信息
Request URL:
http://www.javathinker.net/WEB-INF/lybbs/jsp/topic.jsp?postID=1440本站管理人员 。















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用