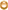- import java.io.IOException;
- import java.io.InputStream;
- import java.io.InputStreamReader;
- import java.io.Reader;
- import java.io.ByteArrayInputStream;
- import org.wltea.analyzer.core.IKSegmenter;
- import org.wltea.analyzer.core.Lexeme;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class ChineseWordCount {
- public static class TokenizerMapper
- extends Mapper< Object, Text, Text, IntWritable>{
- private final static IntWritable one = new IntWritable( 1);
- private Text word = new Text();
- public void map (Object key, Text value, Context context
- ) throws IOException, InterruptedException {
- byte[] bt = value.getBytes();
- InputStream ip = new ByteArrayInputStream(bt);
- Reader read = new InputStreamReader(ip);
- IKSegmenter iks = new IKSegmenter(read, true);
- Lexeme t;
- while ((t = iks.next()) != null)
- {
- word.set(t.getLexemeText());
- context.write(word, one);
- }
- }
- }
- public static class IntSumReducer
- extends Reducer< Text, IntWritable, Text, IntWritable> {
- private IntWritable result = new IntWritable();
- public void reduce (Text key, Iterable<IntWritable> values,
- Context context
- ) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
- public static void main (String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (otherArgs.length != 2) {
- System.err.println( "Usage: wordcount <in> <out>");
- System.exit( 2);
- }
- Job job = new Job(conf, "word count");
- job.setJarByClass(ChineseWordCount.class);
- job.setMapperClass(TokenizerMapper.class);
- job.setCombinerClass(IntSumReducer.class);
- job.setReducerClass(IntSumReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(otherArgs[ 0]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[ 1]));
- System.exit(job.waitForCompletion( true) ? 0 : 1);
- }
- }
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用