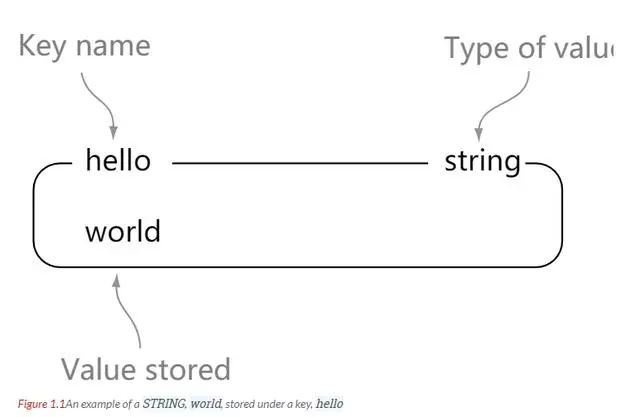
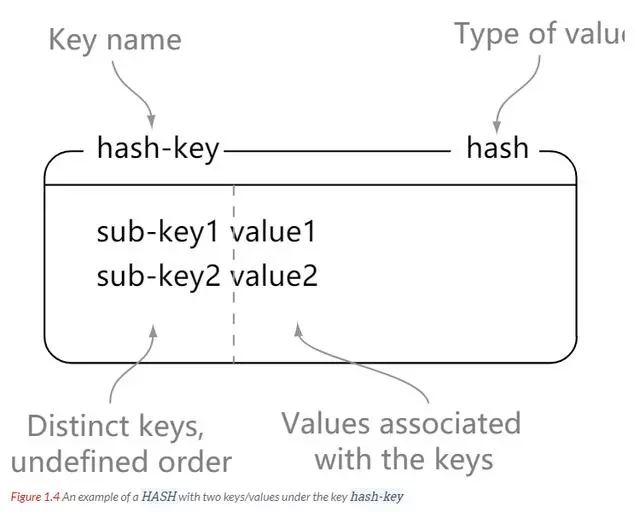
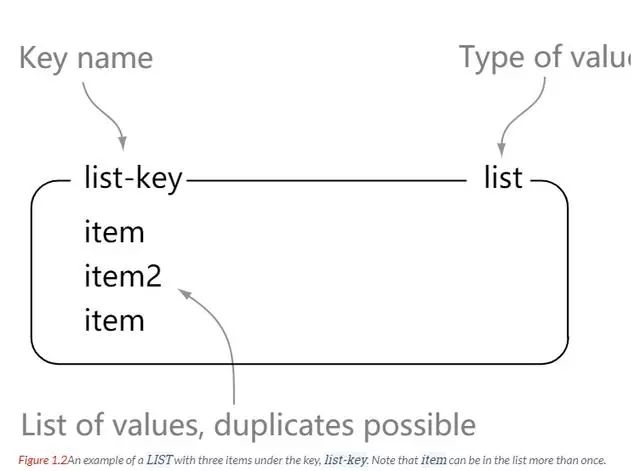
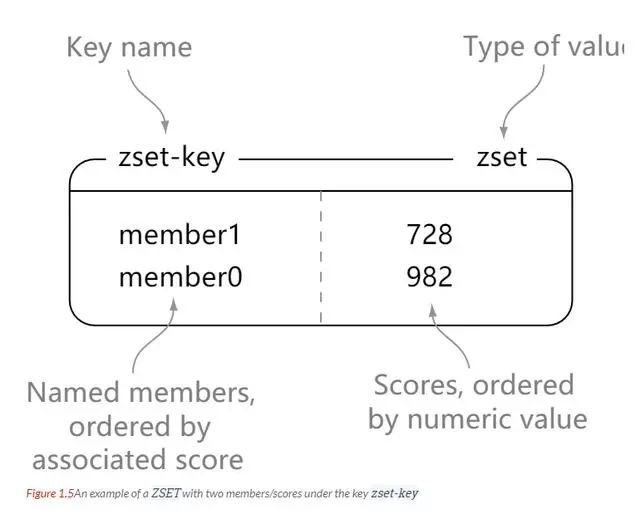
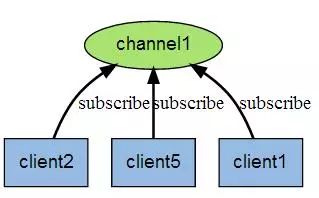
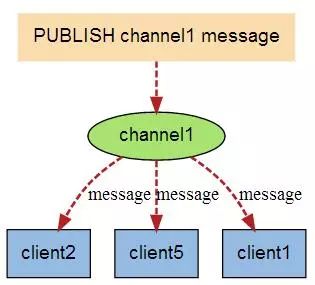
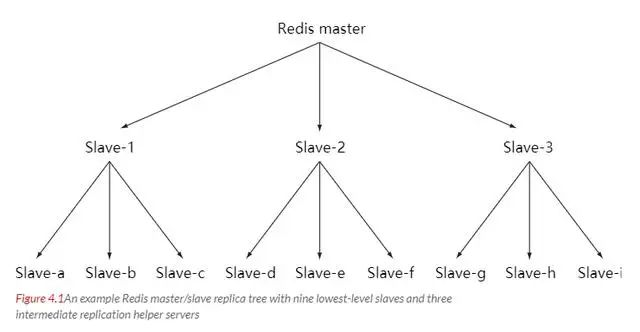
Redis 简介 Redis 支持数据持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。 Redis 不仅仅支持简单的 key - value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储 Redis 支持数据的备份,即 master - slave 模式的数据备份 性能极高 – Redis 读的速度是 110000 次 /s, 写的速度是 81000 次 /s 。 丰富的数据类型 - Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。 原子性 - Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。 其他特性 - Redis 还支持 publish/subscribe 通知,key 过期等特性。 string 理解: string 就像是 java 中的 map 一样,一个 key 对应一个 value hash 理解: 可以将 hash 看成一个 key - value 的集合。也可以将其想成一个 hash 对应着多个 string。 与 string 区别: string 是 一个 key - value 键值对,而 hash 是多个 key - value 键值对。 list list 内的元素是可重复的。 set Zset 简介 实例 redisChat : 批量操作在发送 EXEC 命令前被放入队列缓存。 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余命令依然被执行。也就是说 Redis 事务不保证原子性。 在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。 实例 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令: 这是官网上的说明 From redis docs on transactions: 比如: Redis 事务命令 DISCARD 取消事务,放弃执行事务块内的所有命令。 EXEC 执行所有事务块内的命令。 MULTI 标记一个事务块的开始。 UNWATCH 取消 WATCH 命令对所有 key 的监视。 WATCH key [key …] 监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。 RDB 持久化 AOF 持久化 写命令 同步到磁盘文件上的时机。 always 选项会严重减低服务器的性能 everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。 no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。 连接过程 主服务器创建快照文件,即 RDB 文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。 快照文件发送完毕之后,开始像从服务器发送存储在缓冲区的写命令。 从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令。 主服务器每执行一次写命令,就向从服务器发送相同的写命令。 主从链 最简单的是范围分片,例如用户 id 从 0 ~ 1000 的存储到实例 R0 中,用户 id 从 1001 ~ 2000 的存储到实例 R1中,等等。但是这样需要维护一张映射范围表,维护操作代价高。 还有一种是哈希分片。使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道存储的实例。 客户端分片:客户端使用一致性哈希等算法决定应当分布到哪个节点。 代理分片:将客户端的请求发送到代理上,由代理转发到正确的节点上。 服务器分片:Redis Cluster。 https://blog.51cto.com/u_15065848/2578553 www.javathinker.net
[这个贴子最后由 flybird 在 2021-06-23 15:09:45 重新编辑]
网站系统异常
系统异常信息
Request URL:
http://www.javathinker.net/WEB-INF/lybbs/jsp/topic.jsp?postID=3832本站管理人员 。















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用