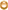|
|
在互联网行业,常用的关系型数据库是MySQL,所以在招聘过程中,面试官一般都会问些关于MySQL的问题,比如MySQL的优化、MySQL的事物特性、隔离级别,以及MySQL索引相关的原理。下面我们就来聊一下MySQL索引相关的内容。
一、索引的数据结构 我们在线上遇到慢查询的情况,一般第一个想到的优化方式就是给where语句后的字段加索引,虽然效果是立竿见影的,但这通常是懒人做法。一方面是因为索引并不是都会生效,可能出现加了索引,查询依旧慢的问题,另一方面,索引会占用磁盘空间。
但是,这并不妨碍我们在遇到慢查询的时候,第一个想到的解决方案就是加索引,那么,为什么加了索引之后,就能优化慢查询,提升查询速度?
其实,索引就是一种优化查询的数据结构,MySQL中的索引就是用B+树实现的。那么为什么MySQL会选择B+树作为索引的实现数据结构呢?它和哈希表、完全平衡二叉树、B树有什么不同?
假设,我们现在有下面的user表:
user
① 哈希表 我们知道,hashMap(1.7)底层就是通过哈希表来实现的,即,数组+链表的方式。
哈希表的缺点有两个: 一、hash冲突,二、只支持精确查询,不支持范围查询,如果我们要某个年龄大于18的用户,如下:
select * from user where name = '关羽'; // 精确查找
select * from user where name > '关羽'; // 范围查找 |
这种情况哈希表并不能实现,所以,哈希表不适合做MySQL的索引数据结构。
②完全平衡二叉树 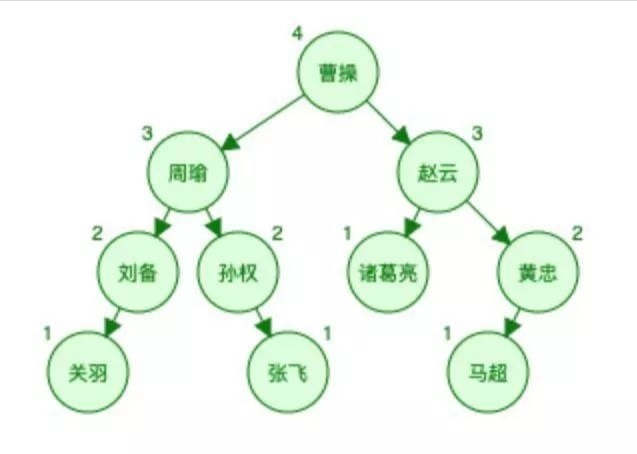
平衡二叉树的每个节点都包含下面四部分信息:
- 左指针,指向左子树
- 键值
- 键值所对应的数据存储地址
- 右指针,指向右子树
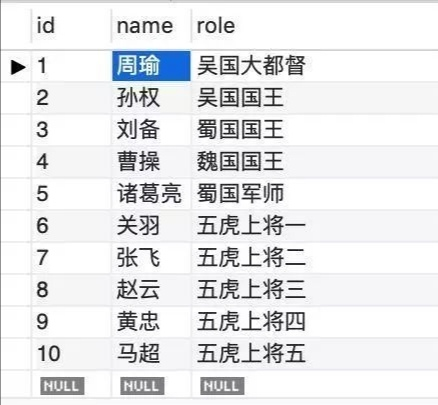
另外,二叉树是有序的,简而言之,就是左节点小于右节点,所以,平衡二叉树是支持范围查找的,但是,在精确查找的时候,会涉及到多次,比如,查刘备,需要查询三次才能找到,比哈希表的精确查找要慢。
③ B树 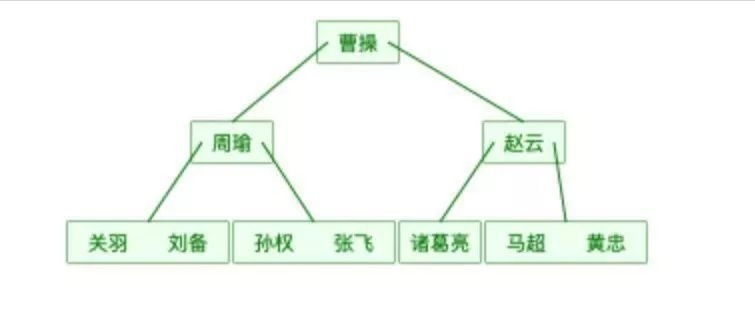
可以看到,B树在层级上比平衡二叉树要少一层,即少一次磁盘IO,原因在于,B树中的一个节点可以存储多个元素。
④ B+树 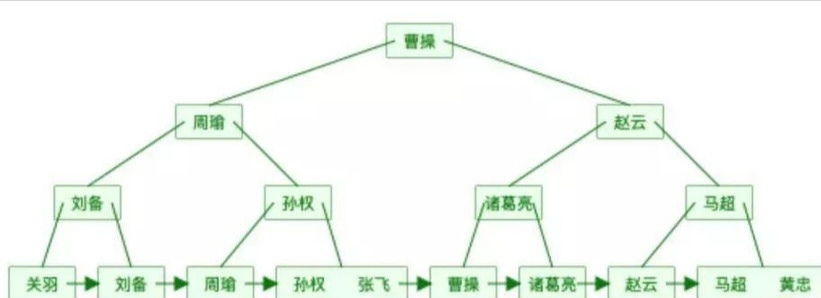
B+树的叶子节点和B树是一样的,只不过冗余了一分非叶子节点的数据
B+树比B树要胖一些,原因在于B+树中的非叶子节点会冗余一分在叶子节点中,并且叶子节点之间用指针相连。
综上,我们可以看出,有三种数据结构是适合做MySQL索引的数据结构的,平衡二叉树、B树、B+树。这三种数据结构都支持精确查找和范围查找,那么为什么MySQL却选中了B+树作为索引的数据结构呢?
其实,索引也是存储元素的,当我们的一个表中的数据越来越多时,对应的索引文件也会越来越大,这样就不能把全部的索引文件放在内存,不得不将索引文件存储在磁盘上,那么选用哪种数据结构,能够提高磁盘的IO效率,就成了参考项。
如果使用完全平衡二叉树来查询“张飞”,则需要四次IO,而使用B树的话,只要三次就可以了,提升了磁盘IO效率,而B+树和B树的非叶子节点是一样的,只不过是叶子节点冗余了一份非叶子节点的数据。所以,在精确查找上,B树和B+树是一样的,而B+树在范围查找上优于B树。
二、 B+树的节点到底多大合适 B+树的一个节点为一页或者一页的整数倍最为合适,因为读取这个节点的时候,是按照一页来读取的,大于或小于一页,会造成资源浪费。
在MySQL的Innodb引擎中,一页的默认大小是16K(如果操作系统的一页大小是4K,那么Mysql中一页=操作系统中4页),可以使用如下命令查看:
| show global status like 'Innodbpagesize'; |
----------------------------
原文链接:https://www.jianshu.com/p/832493393b40
程序猿的技术大观园:www.javathinker.net
|
|















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用