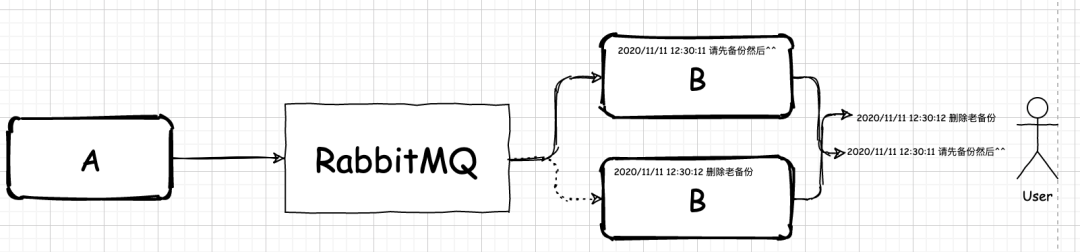
1. 满眼都是自己二十年前的样子,让我们从哈希开始 在 N 年前,互联网的分布式架构方兴未艾。大刘所在的公司由于业务需要,引入了一套由 IBM 团队设计的业务架构。 RabbitMQ 是个单点,它一坏掉,整个系统就会全部瘫痪。 收、发消息的业务系统也是单点。任何一点出现问题,对应队列的消息要么无从消费,要么海量消息堆积。 聊天记录出现了乱序 2. 看来,我们需要增加应用数量了 随着公司的发展,公司的人数也急剧上升,公司内部的 IM 使用人数也跟着多了起来,新问题又随之出现了。 1.我们需要为新加入的这台机器上的应用额外再多增加一个队列 chat02。 2.我们还需要修改下我们的分配消息的规则,把原来的 hash(id) mod 2 修改为 hash(id) mod 3。 3.重新启动发送消息的项目,以便修改的规则生效。 4.把收消息的应用部署到新机器上。 3. 新的问题来了,也许这就是人生吧 由于公司内部很多人在使用这个 IM 工具。有些时候,为了方便,公司的客户还有一些合作方也用起了这个 IM。这让事情变得复杂了起来。起初,开发人员还是像往常一样,每当人们抱怨说收消息过慢的时候,他们就会加一台机器。 4. 思路转起来,队列环起来 新的技术方案的需求本质就是: 增加一个队列 修改分配消息的规则 部署新的机器 随着我们的系统部署越来越多,我们需要手工修改规则的系统也越来越多。 如果消费机器宕机了,我们需要删除队列,同时还需要去删除修改分配消息的规则,等到机器恢复了,我们还要再把分配消息的规则改回去。 1.假设我们需要在消费信息端集群增加一台机器 2.假设消费信息端集群一台机器宕机了 5. 失衡的圆环,压垮骆驼的可能只是一根稻草 假设我们目前有 5 个队列存在,我们的分配规则是 m = hash(id) mod 100。那么,此时,问题就出来了。 6. 从实变虚,也许我们应该更敢想一些 经过上面的论述,我们发现,我们在分配队列时,之所以失衡,是因为我们的队列在圆环上的分配失衡。 m 大于 5 的概率为 95% 7. 理解算法的思想胜于算法的实现 好了,通过实际场景来对于一致性哈希的思想就暂时剖析到这里了。 最后 感谢大家看到这里,文章有不足,欢迎大家指出;如果你觉得写得不错,那就给我一个赞吧。 程序员麦冬, 每天更新行业资讯!https://blog.51cto.com/14849432/2553255 www.javathinker.net
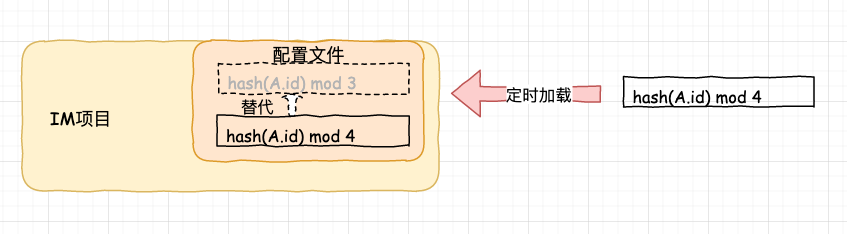
[这个贴子最后由 flybird 在 2020-11-25 10:36:28 重新编辑]
网站系统异常
系统异常信息
Request URL:
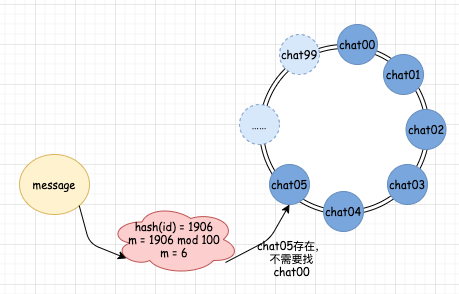
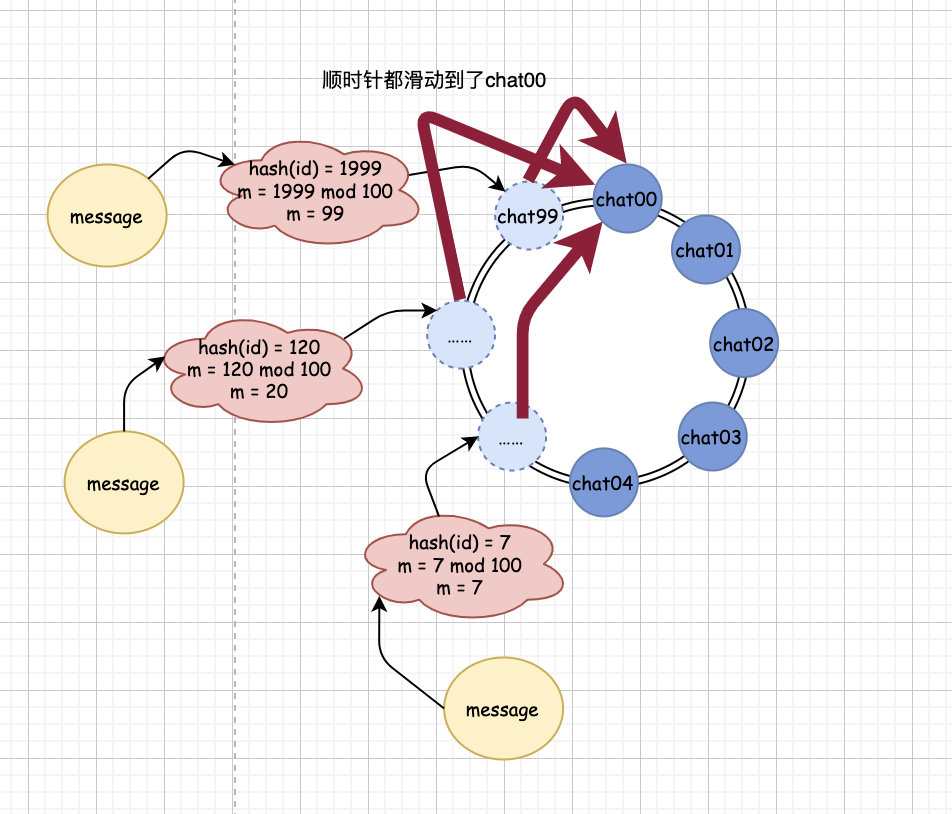
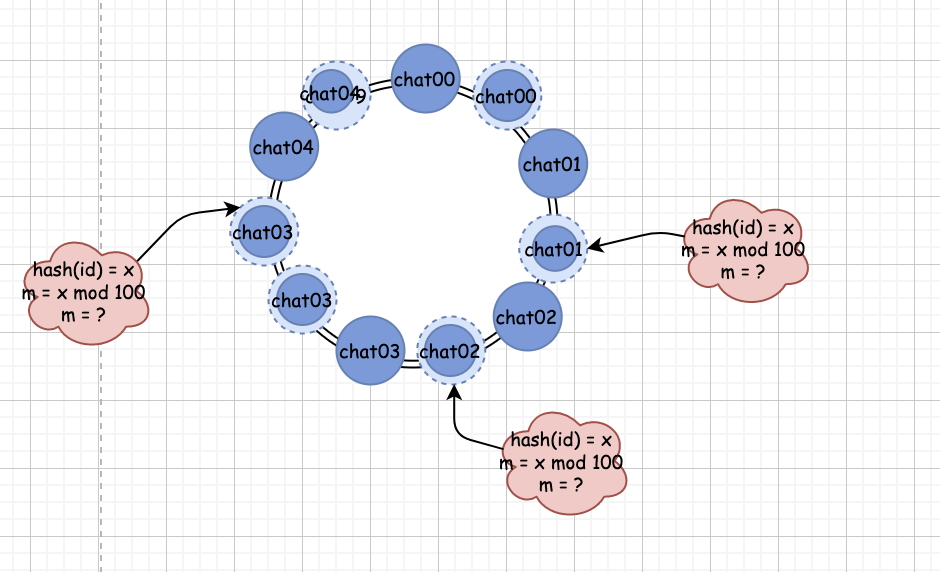
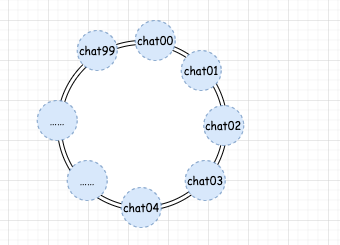
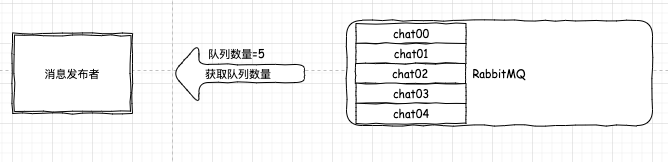
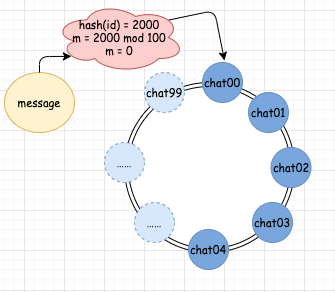
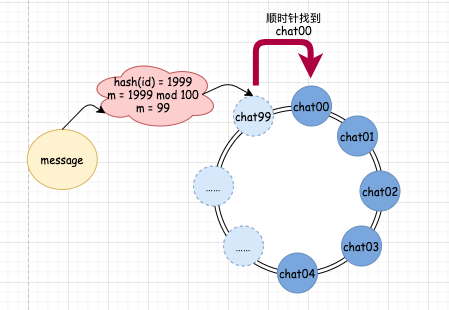
http://www.javathinker.net/WEB-INF/lybbs/jsp/topic.jsp?postID=3600本站管理人员 。















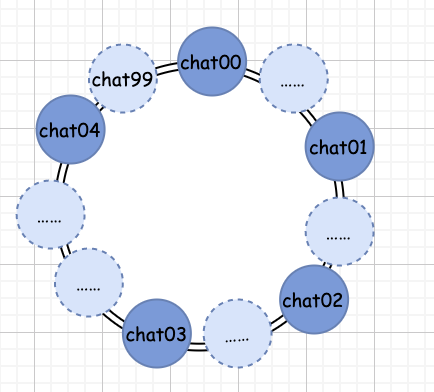
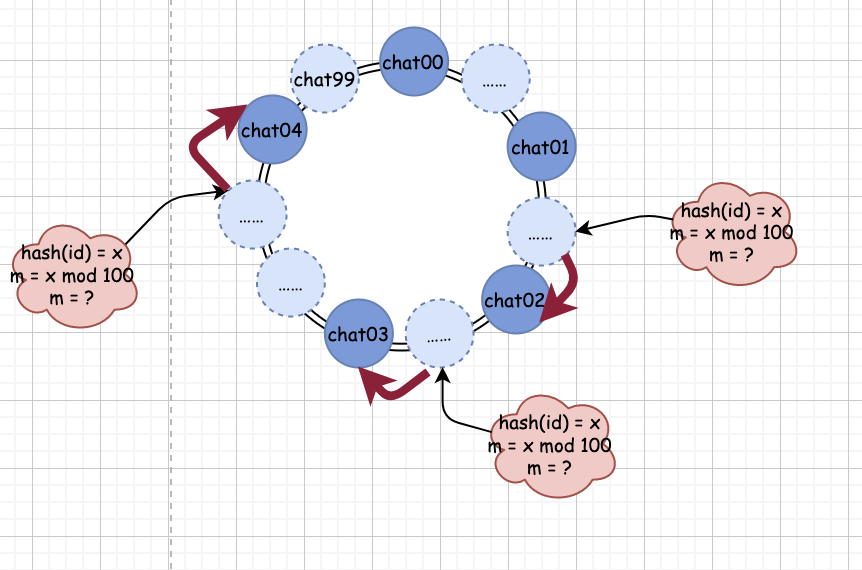
 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用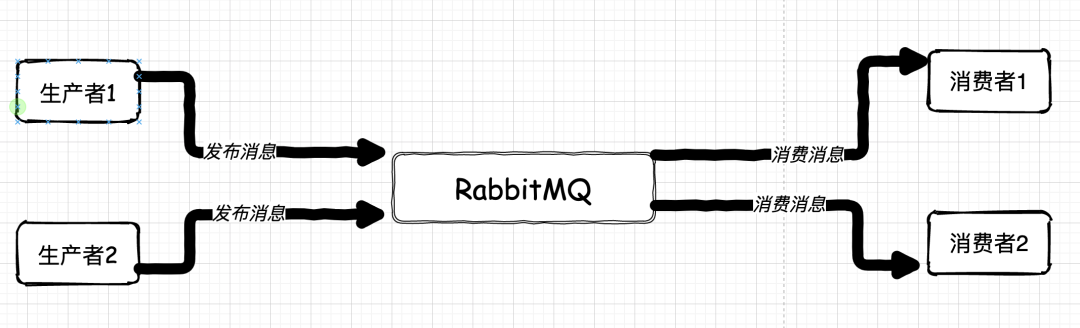
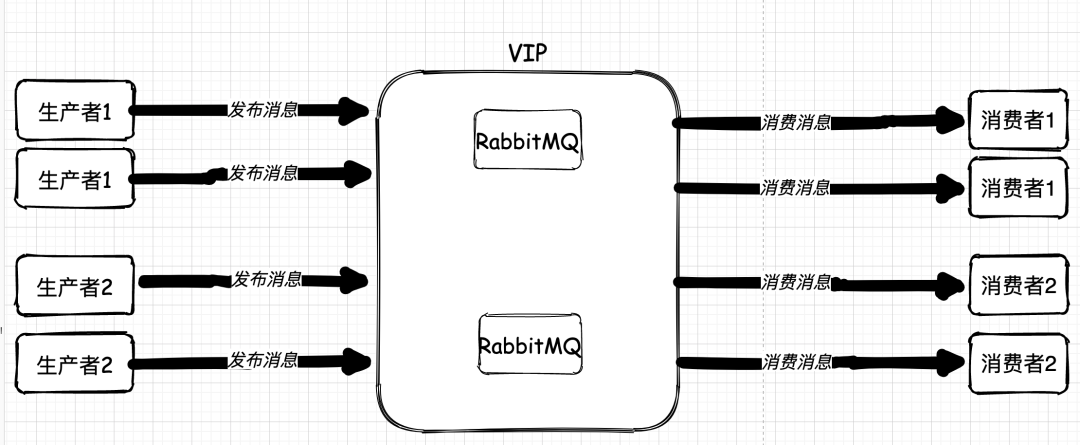
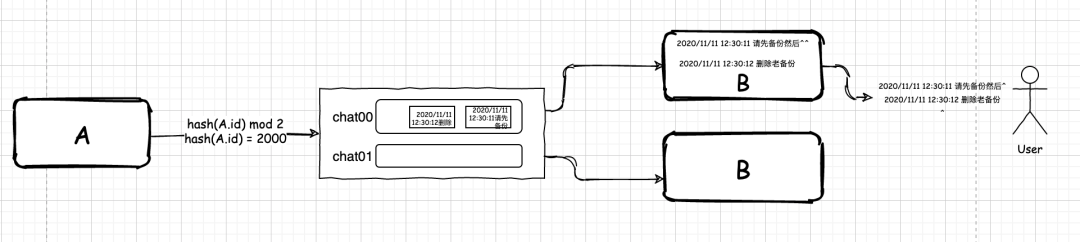
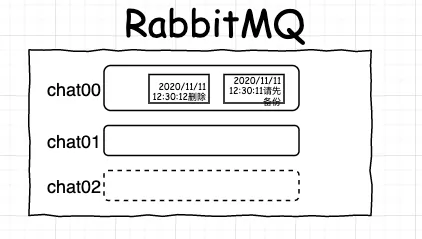
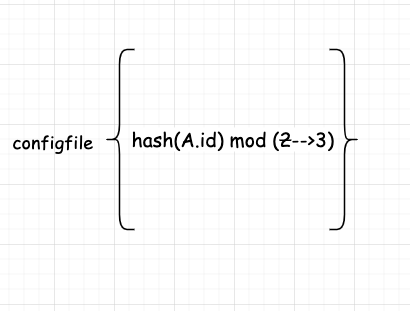
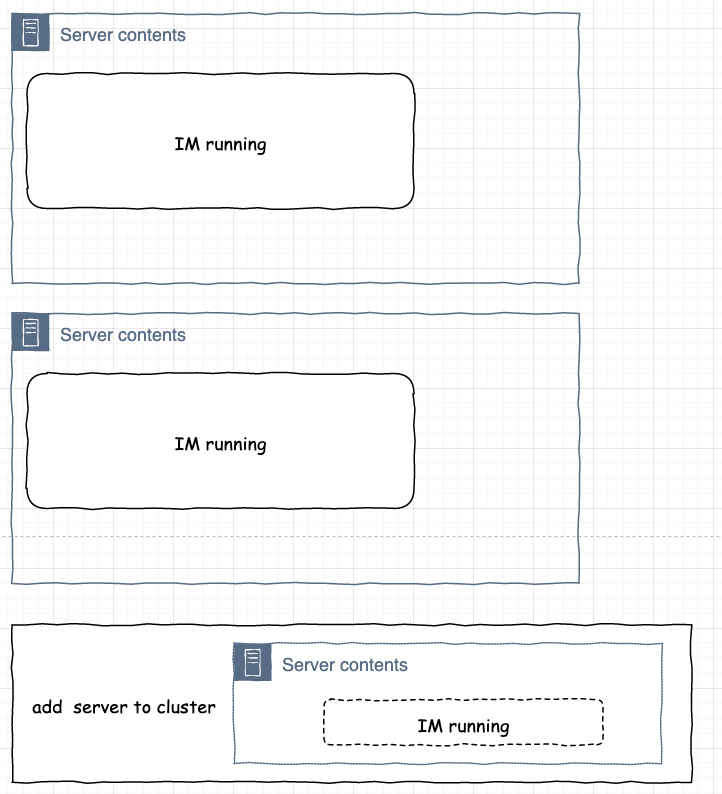
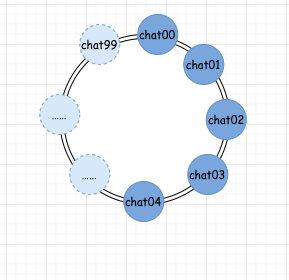
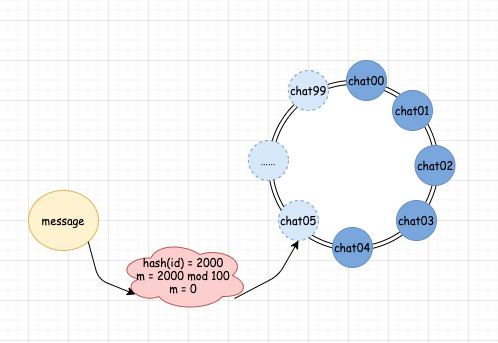 增加机器之后:
增加机器之后: