|
|
场景分析 由于公司zabbix的历史数据存储在elasticsearch中,有个需求是尽可能地把监控的历史数据存储的长一点,最好是一年,目前的情况是三台ES节点,每天监控历史数据量有5G,目前最多可存储一个月的数据,超过30天的会被定时删除,每台内存分了8G,且全部使用机械硬盘,主分片为5,副本分片为1,查询需求一般只获取一周的历史数据,偶尔会有查一个月到两个月历史数据的需求。
节点规划 为了让ES能存储更长的历史数据,我将节点数量增加至4节点,并将部分节点内存提高,部分节点采用SSD存储
192.168.179.133 200GSSD 4G内存 tag:hot node.name=es1
192.168.179.134 200GSSD 4G内存 tag:hot node.name=es2
192.168.179.135 500GHDD 64G内存 tag:cold node.name=es3
192.168.179.136 500GHDD 64G内存 tag:cold node.name=es4 |
优化思路 对数据mapping重新建模,对str类型的数据不进行分词,采用冷热节点对数据进行存储,前七天数据的索引分片设计为2主1副,索引存储在热节点上,超过七天的数据将被存储在冷节点,并修改冷节点上的副本分片数为0,ES提供了一个shrink的api来进行压缩。由于ES是基于Lucene的搜索引擎,Lucene的索引由多个segment组成,每一个段都会消耗文件句柄,内存和CPU运行周期,段数量过多会使资源消耗变大,搜索也会变慢,这里我将前一天的索引分片强制合并为1个segment,修改refresh的时间间隔至60s,减少段的产生频率。对超过3个月的索引进行关闭。以上操作均使用ES的管理工具curator来定时执行。
zabbix与ES的对接操作 1.修改/etc/zabbix/zabbix_server.conf,添加如下内容 ES地址填写集群中任意一个节点就可以
HistoryStorageURL=192.168.179.133:9200
HistoryStorageTypes=str,text,log,uint,dbl
HistoryStorageDateIndex=1 |
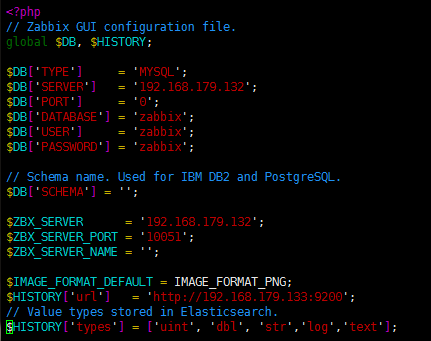
2.修改/etc/zabbix/web/zabbix.conf.php,添加如下内容 global $DB, $HISTORY;
$HISTORY['url'] = 'http://192.168.179.133:9200';
// Value types stored in Elasticsearch.
$HISTORY['types'] = ['str', 'text', 'log','uint','dbl']; |
3.修改ES配置文件,添加冷热节点的标签 vim elasticsearch.yml
热节点配置
冷节点配置
3.在es上创建模板和管道 每种数据类型的模板都需要创建,可以根据elasticsearch.map文件来获取api的信息,模板定义内容有匹配的索引,主副分片数设置,refresh间隔,新建索引分配节点设置以及mapping的设置,这里我只是以uint和str数据的索引为例
PUT _template/uint_template
{
"template": "uint*",
"index_patterns": ["uint*"],
"settings" : {
"index" : {
"routing.allocation.require.box_type": "hot",
"refresh_interval": "60s",
"number_of_replicas" : 1,
"number_of_shards" : 2
}
},
"mappings" : {
"values" : {
"properties" : {
"itemid" : {
"type" : "long"
},
"clock" : {
"format" : "epoch_second",
"type" : "date"
},
"value" : {
"type" : "long"
}
}
}
}
}
PUT _template/str_template
{
"template": "str*",
"index_patterns": ["str*"],
"settings" : {
"index" : {
"routing.allocation.require.box_type": "hot",
"refresh_interval": "60s",
"number_of_replicas" : 1,
"number_of_shards" : 2
}
},
"mappings" : {
"values" : {
"properties" : {
"itemid" : {
"type" : "long"
},
"clock" : {
"format" : "epoch_second",
"type" : "date"
},
"value" : {
"index" : false,
"type" : "keyword"
}
}
}
}
} |
定义管道的作用是对写入索引之前的数据进行预处理,使其按天产生索引。
PUT _ingest/pipeline/uint-pipeline
{
"description": "daily uint index naming",
"processors": [
{
"date_index_name": {
"field": "clock",
"date_formats": ["UNIX"],
"index_name_prefix": "uint-",
"date_rounding": "d"
}
}
]
}
PUT _ingest/pipeline/str-pipeline
{
"description": "daily str index naming",
"processors": [
{
"date_index_name": {
"field": "clock",
"date_formats": ["UNIX"],
"index_name_prefix": "str-",
"date_rounding": "d"
}
}
]
} |
4.修改完成后重启zabbix,并查看zabbix是否有数据
| systemctl restart zabbix-server |
使用curator对索引进行操作 curator官方文档地址如下
https://www.elastic.co/guide/en/elasticsearch/client/curator/5.8/installation.html
1.安装curator| pip install -U elasticsearch-curator |
2.创建curator配置文件 mkdir /root/.curator
vim /root/.curator/curator.yml
---
client:
hosts:
- 192.168.179.133
- 192.168.179.134
port: 9200
url_prefix:
use_ssl: False
certificate:
client_cert:
client_key:
ssl_no_validate: False
http_auth:
timeout: 30
master_only: False
logging:
loglevel: INFO
logfile:
logformat: default
blacklist: ['elasticsearch', 'urllib3'] |
3.编辑action.yml,定义action 将7天以前的索引分配到冷节点
1:
action: allocation
description: "Apply shard allocation filtering rules to the specified indices"
options:
key: box_type
value: cold
allocation_type: require
wait_for_completion: true
timeout_override:
continue_if_exception: false
disable_action: false
filters:
- filtertype: pattern
kind: regex
value: '^(uint-|dbl-|str-).*$'
- filtertype: age
source: name
direction: older
timestring: '%Y-%m-%d'
unit: days
unit_count: 7 |
将前一天的索引强制合并,每个分片1个segment。
2:
action: forcemerge
description: "Perform a forceMerge on selected indices to 'max_num_segments' per shard"
options:
max_num_segments: 1
delay:
timeout_override: 21600
continue_if_exception: false
disable_action: false
filters:
- filtertype: pattern
kind: regex
value: '^(uint-|dbl-|str-).*$'
- filtertype: age
source: name
direction: older
timestring: '%Y-%m-%d'
unit: days
unit_count: 1 |
修改冷节点得副本分片数量为0
3:
action: replicas
description: "Set the number of replicas per shard for selected"
options:
count: 0
wait_for_completion: True
max_wait: 600
wait_interval: 10
filters:
- filtertype: pattern
kind: regex
value: '^(uint-|dbl-|str-).*$'
- filtertype: age
source: name
direction: older
timestring: '%Y-%m-%d'
unit: days
unit_count: 7 |
对超过六个月的索引进行关闭
4:
action: close
description: "Close selected indices"
options:
delete_aliases: false
skip_flush: false
ignore_sync_failures: false
filters:
- filtertype: pattern
kind: regex
value: '^(uint-|dbl-|str-).*$'
- filtertype: age
source: name
direction: older
timestring: '%Y-%m-%d'
unit: days
unit_count: 180 |
超过一年的索引进行删除
5:
action: delete_indices
description: "Delete selected indices"
options:
continue_if_exception: False
filters:
- filtertype: pattern
kind: regex
value: '^(uint-|dbl-|str-).*$'
- filtertype: age
source: name
direction: older
timestring: '%Y-%m-%d'
unit: days
unit_count: 365 |
4.执行curator进行测试
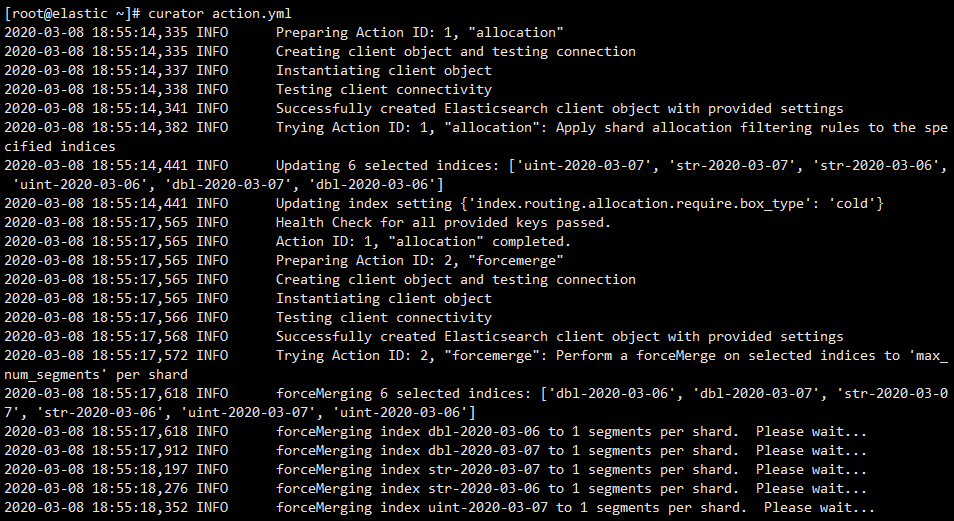
5. 将curator操作写进定时任务,每天执行 crontab -e
10 0 * * * curator /root/action.yml |
以上就是对zabbix后端存储elasticsearch存储优化的全部实践,参考链接
https://www.elastic.co/cn/blog/hot-warm-architecture-in-elasticsearch-5-x
欢迎关注个人公号“没有故事的陈师傅”

----------------------------
原文链接:https://blog.51cto.com/12970189/2476469
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-03-15 10:18:41 重新编辑]
|
网站系统异常
| 系统异常信息 |
Request URL:
http://www.javathinker.net/WEB-INF/lybbs/jsp/topic.jsp?postID=2712
java.lang.NullPointerException
如果你不知道错误发生的原因,请把上面完整的信息提交给本站管理人员。
|
|















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用