|
|
基于spark-streaming实时推荐系统(一) 前言
随着互联网的飞速发展,如何能够让用户在广袤的互联网中获取到他所想要的,这时候人们有了搜索引擎。搜索引擎好比一个仓库,它需要事先储藏大量的资源,你需要什么都可以从中获取得到。这种被动索取的方式无形之中也注定了搜索引擎在某个范围内只能一家独大。科技改变着人们的生活,随着大数据时代的到来,传统被动等候来获取的方式由于其需要的前期投入较大,准确性往往也不能满足用户的真正需求,在此背景之下,推荐引擎遍广泛的被大家所接收,它的出现改变了系统被动的一面,它就好似跟踪导弹,只要你出现在互联网之中,就可以时刻为你推荐。
前期已经写了推荐系统离线计算的博文,主要是根据CF寻找相似,这种离线的推荐在计算周期内推荐结果不发生改变。个性化推荐则需要用户发生行为而实时为其推送推荐结果。
下面简单介绍下spark-streaming实时推荐系统搭建
系统边界
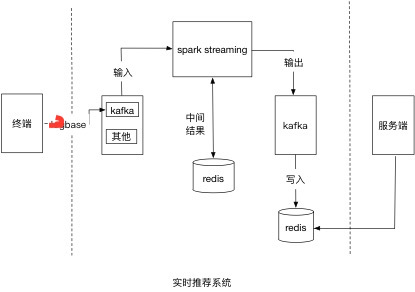
依托于一套可以实时采集到用户行为的日志采集系统,详情可以参见用户实时行为数据采集 将数据实时推送至kafka中,spark-streaming实时读取kafka中数据,进行特定的业务规则处理。这里会用到UpdateStateByKey方法,有兴趣的朋友可以去查阅相关资料了解此方法的原理及实现。
数据流
1. 数据输入:
Kafka
Hosts:
Topic:
2. 中间结果:
Redis
scala编写,需要注意如何将结果保存至redis,常见的有序列号和json。
3. 结果输出
Kafka:考虑未来多系统消费,信息丰富化
Hosts:
Topic: |
kafka接数
val sparkConf = new SparkConf() .setAppName( "realtimeRecommendation")
. set( "spark.streaming.backpressure.enabled", "true")
val ssc = new StreamingContext(sparkConf, Seconds( 15))
ssc .checkpoint( "/checkpoint/pztyz")
val kafkaConfig = Map( "metadata.broker.list" -> "kafka地址")
val topics = Set(sparkConf .get( "topic"))
val stream = KafkaUtils .createDirectStream [ String, String, StringDecoder, StringDecoder ] (ssc, kafkaConfig, topics) |
业务逻辑实现
这里可以自由发挥
结束语
为了真实准确的为用户进行实时推荐,最终还是要依赖历史数据进行整合,需要依赖一套完整的离线推荐系统作为数据支撑。未完待续。
----------------------------
原文链接:https://blog.csdn.net/pztyz314151/article/details/53025728
程序猿的技术大观园:www.javathinker.net
[这个贴子最后由 flybird 在 2020-03-22 12:06:58 重新编辑]
|
|
















 消息
消息 查看
查看 搜索
搜索 好友
好友 邮件
邮件 复制
复制 引用
引用